

Next: Abstracts O-Z
Up: abstracts
Previous: Abstracts A-D
Aïcha El Golli, INRIA-Rocquencourt, Brieuc Conan-Guez,
and Fabrice Rossi, University of Paris-Dauphine, ``A
Self-Organizing Map for Dissimilarity Data''
Abs:
Treatment of complex data (for example symbolic data,
semi-structured data, or functional data)
cannot be easily done by clustering methods that are based on
calculating the center of gravity.
We present in this paper an extension of self-organizing maps
to dissimilarity data. This extension allows to apply this
algorithm to numerous types of data in a convenient way.
José Luis Espinoza, Instituto Technológico de
Costa Rice, and Javier Trejos, CIMPA, ``Genetic Variable
Selection in Linear Regression''
Abs:
We study the application of genetic algorithms in variable
selection problems for multiple linear regression, minimizing
the least squares criterion.
The algorithm is based on a chromosomic representation of variables that are
considered in the least squares model.
A binary chromosome indicates the presence (1) or absence (0)
of a variable in the model.
The fitness function is based on the determination coefficient, weighting
also the quantity of variables that enter into the model:
where 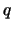 is the number of absent variables, and
is the number of absent variables, and 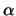 is a parameter.
The usual genetic operators, including roulette-wheel selection,
crossover, and mutation are implemented.
Comparisons are performed with benchmark data sets, and this finds
promising results.
is a parameter.
The usual genetic operators, including roulette-wheel selection,
crossover, and mutation are implemented.
Comparisons are performed with benchmark data sets, and this finds
promising results.
Anuska Ferligoj and
Vladimir Batagelj, University of Ljubljana, and Patrick Doreian,
University of Pittsburgh, ``Blockmodeling as a Clustering Problem''
Abs:
The goal of blockmodeling is to reduce a large, potentially incoherent
network to a smaller comprehensible structure that can be interpreted
more readily. One of the main procedural goals of blockmodeling is to
identify, in a given network (defined by a set of units and one or
several relations) clusters of units that share structural characteristics
defined in terms of the relation. The units within a cluster
have the same or similar connection patterns to other units.
The set of clusters form a clustering (e.g., a partition, hierachy).
The problem of establishing a partition of units in a network in terms of
a selected type of equivalence is a special case of clustering problem
that can be formulated as an optimization problem: determine the
clustering that has the minimal value of a criterion function across all
possible feasible clusterings. Criterion functions can be constructed
indirectly as a function of a compatible (dis)similarity measure between
pairs of units (a classical clustering problem), or directly as a function
measuring the fit of a clustering to an ideal one with perfect relations
within each cluster and between clusters according to the considered types
of connections (equivalence). A local optimization procedure (a relocation
algorithm) can be used if the criterion function is defined directly.
This optimizational approach permits to generalize equivalences and to
consider pre-specification of a blockmodel by starting with a blockmodel
that is specified in terms of substance prior to an analysis. In this case
given a network, set of types of ideal blocks, and a reduced model,
a solution (a clustering) can be determined which minimizes the criterion
function. The proposed approach can be applied also to two-mode relational
data. The key idea is that the rows and columns of a two-mode matrix are
clustered simultaneously but in different ways.
Several examples will be given to illustrate the proposed generalized
approach to blockmodeling.
Bernard Fichet, University of Aix Marseille II, ``Theory for the
Cartesian Product of 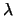 -Quasi-Hierarchies''
Abs:
Quasi-hierarchies, as were introduced by Diatta and
Fichet (1994), or Bandelt and
Dress (1994), extend the hierarchical structures. The main axiom is the one
of Bandelt-Dress weak hierarchies :
-Quasi-Hierarchies''
Abs:
Quasi-hierarchies, as were introduced by Diatta and
Fichet (1994), or Bandelt and
Dress (1994), extend the hierarchical structures. The main axiom is the one
of Bandelt-Dress weak hierarchies :
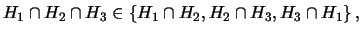 for every triple
for every triple
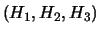 of clusters. A natural generalisation is given for any
integer
of clusters. A natural generalisation is given for any
integer
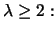
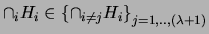 for every
collection of clusters
for every
collection of clusters
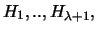 see Bandelt and Dress (1994)
and Diatta (1997), leading to the so-called -quasi-hierarchies.
Pseudo-hierarchies (''pyramids''), the union of two hierarchies after
closure and structures associated with additive trees provide some famous
examples of quasi-hierarchies
see Bandelt and Dress (1994)
and Diatta (1997), leading to the so-called -quasi-hierarchies.
Pseudo-hierarchies (''pyramids''), the union of two hierarchies after
closure and structures associated with additive trees provide some famous
examples of quasi-hierarchies
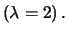 Another example
is offered by the Cartesian product of two hierarchies, Fichet (1998). By
definition, the Cartesian product
Another example
is offered by the Cartesian product of two hierarchies, Fichet (1998). By
definition, the Cartesian product 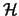 =
=
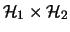 of two systems of clusters
of two systems of clusters 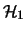 and
and 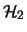 on
on 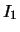 and
and 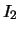 respectively, is the system on
respectively, is the system on
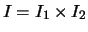 of
clusters of the type
of
clusters of the type
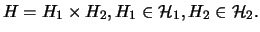 We here extend the above-mentioned property, by showing that given a
We here extend the above-mentioned property, by showing that given a
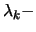 quasi-hierarchy
quasi-hierarchy 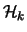 on
on 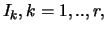 the product
the product
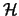 =
=
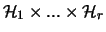 is a -quasi-hierarchy on
is a -quasi-hierarchy on
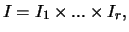 with
with
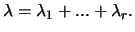
Ernest Fokoue, Ohio State University, ``Variational
Approximation for Gaussian Process Classifiers''
Abs:
Gaussian process priors have been successfully used in the construction
of highly accurate
Bayesian classifiers. However, the quality of estimation and prediction
with such classifiers
always heavily depends on how well the intractable posterior is
approximated. In this talk, I will
describe the adaptation of a variational mean field approximation to
Bayesian probit
classification. The application of this method to some benchmark
datasets is shown to produce very good results.
María Teresa Gallegos and Gunter Ritter,
Universität Passau, ``A Breakpoint Analysis for Clustering''
Abs:
In order to subdivide a Euclidean data set
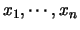 in
in 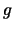 homogeneous groups, the (nowadays classical)
determinant criterion of cluster analysis (Friedman and
Rubin (1967), Scott and Symons (1971) postulates
as estimator the partition which minimizes the determinant of the
pooled SSP matrix
homogeneous groups, the (nowadays classical)
determinant criterion of cluster analysis (Friedman and
Rubin (1967), Scott and Symons (1971) postulates
as estimator the partition which minimizes the determinant of the
pooled SSP matrix 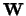 . The estimators of the mean vectors and
common covariance matrix of the underlying normal populations are
the sample means and the pooled scatter matrix
. The estimators of the mean vectors and
common covariance matrix of the underlying normal populations are
the sample means and the pooled scatter matrix 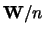 ,
respectively, defined by the estimated partition.
To robustify the clustering procedure, Rocke and
Woodruff (1999) introduced a trimmed version: given a
trimming level
,
respectively, defined by the estimated partition.
To robustify the clustering procedure, Rocke and
Woodruff (1999) introduced a trimmed version: given a
trimming level
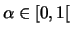 , find the subset of size
, find the subset of size
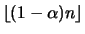 of the data which is optimal w.r.t. the
determinant criterion.
A measure of robustness of an estimator is its breakdown value,
Hodges (1967). We compute the breakdown values of the mean
vectors and of the SSP matrix of the trimmed determinant criterion. It
turns out that the latter is positive under very general conditions, a
fact that pleads for the robustness of the trimmed determinant
criterion.
of the data which is optimal w.r.t. the
determinant criterion.
A measure of robustness of an estimator is its breakdown value,
Hodges (1967). We compute the breakdown values of the mean
vectors and of the SSP matrix of the trimmed determinant criterion. It
turns out that the latter is positive under very general conditions, a
fact that pleads for the robustness of the trimmed determinant
criterion.
Sugnet Gardner and Niel le Roux, University of Stellanbosch,
``Modified Biplots for Enhancing
Two-Class Discriminant Analysis''
Abs:
When applied to discriminant analysis (DA) biplot methodology leads to
useful graphical displays
for describing and quantifying multidimensional separation and overlap
among classes. The
principles of ordinary scatterplots are extended in these plots by
adding information of all variables on the plot. However, we show that
there are fundamental differences between two-class DA
problems and the case 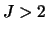 : describing overlap in the two-class situation
is relatively straightforward using density estimates but adding information
by way of multiple axes to the plot can be ambiguous unless care is taken.
Contrary to this, describing overlap for classes is relatively more
complicated but the fitting of multiple calibrated axes to biplots is well
defined.
We propose modifications to existing biplot methodology leading to useful
biplots for use in the important case of two-class DA problems.
: describing overlap in the two-class situation
is relatively straightforward using density estimates but adding information
by way of multiple axes to the plot can be ambiguous unless care is taken.
Contrary to this, describing overlap for classes is relatively more
complicated but the fitting of multiple calibrated axes to biplots is well
defined.
We propose modifications to existing biplot methodology leading to useful
biplots for use in the important case of two-class DA problems.
Wolfgang Gaul, University of Karlsruhe, ``Web Mining and Its
Interrelations to Classification Data Mining and Market Research''
Abs:
Web mining is still a challenge to data analysts as well as
researchers in related fields, for whom, depending on the target
audience, different starting points can be presented.
From an application oriented point of view examples concerning online
visibility (How to attract web visitors?), visualization of
recommender system results (How to visualize the searching, viewing,
and buying behavior of online shoppers?), and web robot detection (How
to distinguish between robots and human web visitors?) will be used as
introduction where in each case algorithmic aspects are just sketched.
From a mathematical perspective it is shown how so-called
``clickstreams'' or navigation paths of web users can be analyzed. Path
fragments as sequences of subpaths connected by wildcards describe
interesting substructures for the analysis of frequent generalized
navigational patterns. In this context the label ``substructures'' is
used as basis for a more general framework in which frequent
substructures are detected by modifications of the a priori algorithm
where sets, sequences, and generalized sequences (of nodes of the site
graph visited while browsing the web) are just special cases. The
methodology is explained and examples are presented to show how web
mining can enhance customer relationship management and help to tackle
web controlling issues.
F. Giannandrea, Catholic University of Sacred Hearth, and
D. F. Iezzi, University ``La Sapienza'',
``A Method to Classify Hospital Workers with Lower Back Pain''
Abs:
Low back pain is almost universal experience among adults, and the
prevalence of disability back pain has increased greatly during the
past 20 years. Epidemiological studies have provided ample evidence
that physical work factors like high physical load, manual material
handling and patient handling are associated with the occurrence of
low back pain (3). Hospital workers, particularly ward nurses, are
known to be at high risk for back pain, with patient-handling tasks
being implicated in most cases (6). In several studies perceived
disability associated with low back pain has been collected by
different questionnaires and a variety of scales (2, 5). The most
popular questionnaire is Oswestry Disability Index (ODI) (1, 2). The
aim of this paper is to classify hospital workers with lumbar
disability by cluster analysis of their responses to the ODI (4). A
classification tool was developed to categorize different lumbar
disability classes (7).
E. Graubins and David Grossman, Illinois Institute of
Technology,
``Applying Hybrid Modeling to Predict the Stock Market''
Abs:
Many voting algorithms exist for classification problems. These algorithms
typically use the results of numerous classifiers for an entire data set. We
identify good classifiers for a particular training set and then apply
separate classifiers for given portions of the dataset based on their
performance. We have some initial results on a stock market data set that
shows the potential for this approach. Our initial work has exhibited an
accuracy level of over 90%.
Vahan Grigoryan, Donald Chiarulli, and Milos Hauskrecht,
University of Pittsburgh, ``Subject
Filtering for Passive Biometric Monitoring''
Abs:
Biometric data can provide useful information about
the person's overall
wellness. However, the invasiveness of the data collection process often
prevents their wider exploitation. To alleviate this difficulty we are
developing a biometric monitoring system that relies on nonintrusive
biological traits such as speech and gait. We report on the
development of the pattern recognition module of the system that is
used to filter out nonsubject data. Our system builds upon a number of
signal processing and statistical machine learning techniques to
process and filter the data, including, Principal Component Analysis
for feature reduction, the Naive Bayes classifier for the gait
analysis, and the Mixture of Gaussian classifiers for the voice
analysis. The system achieves high accuracy in filtering non-subject
data, more specifically, 84% accuracy on the gait channel and 98%
accuracy on the voice signal. These results allow us to generate
sufficiently accurate data streams for health monitoring purposes.
Patrick J. F. Groenen, Erasmus University, and Michael W.
Trosset, College of William & Mary,
``Fast Multidimensional Scaling of Large Data Sets''
Abs:
Multidimensional scaling (MDS)
algorithms tend to be slow if thenumber of objects is large, say
larger than n=500 objects. In someapplications such as dimension
reduction, molecular confirmation,and data mining, larger data sets
are available but traditionalMDS algorithms get too slow. However, if
so much data areavailable, it generally suffices to use only a
fraction. Formissing data, the SMACOF algorithm (see, e.g., De Leeuw
andHeiser, 1977, De Leeuw 1988, and Borg and Groenen, 1997) requiresa
Moore-Penrose inverse of an n times n matrix. For large n,
thecomputation of this inverse becomes prohibitive. Here we proposeto
impose missing data according to a symmetric circulant designs.An
advantage of this design is that a very efficientimplementation of the
Moore-Penrose inverse is available (Gowerand Groenen, 1991).In this
presentation, we show a working prototype programmed inMatLab. In a
small simulation study, we investigate how well thetechnique is able
to find true underlying representations.
Alain Guénoche, Institute de Mathématiques de
Luminy-CNRS, ``Clustering By Vertex Density in a Graph''
Abs:
In this paper we introduce a new principle for two classical
problems in clustering: obtaining a set of partial classes and a
partition on a set 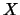 of
of 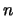 elements. These structures are built
from a distance
elements. These structures are built
from a distance 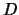 and a threshold value
and a threshold value 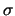 giving a
threshold graph on with maximum degree
giving a
threshold graph on with maximum degree 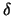 . The method is
based on a density function
. The method is
based on a density function
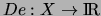 which
is computed first from . Then, the number of classes, the
classes, and the partitions are established using only this density
function and the graph edges, with a computational complexity of
which
is computed first from . Then, the number of classes, the
classes, and the partitions are established using only this density
function and the graph edges, with a computational complexity of
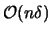 . Monte Carlo simulations, from random Euclidian
distances, validate the method.
. Monte Carlo simulations, from random Euclidian
distances, validate the method.
David Hand, Imperial College, ``Academic Obsessions and
Classification Realities: Ignoring Practicalities in Supervised
Classification''
Abs:
Supervised classification methods have been the focus of a vast amount
of research in recent decades, within a variety of intellectual
disciplines, including statistics, machine learning, pattern
recognition, and data mining. Highly sophisticated methods have been
developed, using the full power of recent advances in computation.
Many of these methods would have been simply inconceivable to earlier
generations. However, most of these advances have largely taken place
within the context of the classical supervised classification paradigm
of data analysis. That is, a classification rule is constructed based
on a given `design sample' of data, with known and well-defined
classes, and this rule is then used to classify future objects. This
paper argues that this paradigm is often, perhaps typically, an
over-idealisation of the practical realities of supervised
classification problems. Furthermore, it is also argued that the
sequential nature of the statistical modelling process means that the
large gains in predictive accuracy are achieved early in the modelling
process. Putting these two facts together leads to the suspicion that
the apparent superiority of the highly sophisticated methods is often
illusory: simple methods are often equally effective or even superior
in classifying new data points.
André Hardy and Pascale Lallemand, University of Namur,
``The Clustering of Symbolic
Objects Described by Multi-Valued and Modal Variables''
Abs:
In this paper we investigate the problem of the determination of the
number of clusters for symbolic objects
described by multi-valued and modal variables. Three dissimilarity
measures are selected in order to define distances
on the set of symbolic objects. Methods for the determination of the
number of clusters are applied to hierarchies of partitions produced
by four hierarchical clustering methods, and to sets of partitions
given by the symbolic clustering procedure SCLUST. Two real data sets
are analysed.
Georges Hébrail, ENST, and Yves Lechevallier, INRIA,
``Building Small Scale
Models of Multi-Entity Databases by Clustering''
Abs:
A framework is proposed to build small scale models of very large
databases describing several entities and their relationships.
In the first part, it is shown that the use of sampling is not a
good solution when several entities are stored in a database.
In the second part, a model is proposed which is based on clustering
all entities of the database and storing aggregates
on the clusters and on the relationships between the clusters.
The last part of the paper discusses the different problems which are
raised by this approach.
Some solutions are proposed: in particular, the link with symbolic
data analysis is established.
David I Holmes and Daniel W Crofts, The College of New
Jersey, ``The Diary of a Public Man: A Case Study in Traditional and
Non-Traditional Authorship Attribution''
Abs:
In 1879 the North American Review published in four separate monthly
installments excerpts from ``The Diary of a Public Man'' in which the
name of the diarist was withheld. It was, or purported to be, a diary
kept during the ``secession winter'' of 1860-61. It appeared to offer
verbatim accounts of behind-the-scenes discussions at the very highest
levels during the greatest crisis the US had ever faced. Interest in
this real or purported diary was considerable. The diarist had access
to a wide spectrum of key officials, from the South as well as the
North, gave a number of striking anecdotes about Abraham Lincoln, and
provided an important account of events at Washington during the
critical days just before the Civil War.
This paper argues that the diarist was not Samuel Ward as has been
suggested; it was, instead, William Hurlbert. The preponderance of
the evidence also suggests that the Diary may well be a legitimate
historical document.
For testing and validating the stylometric techniques involved in this
study, preliminary textual samples were taken from prominent diarists
of that era, i.e., George Templeton Strong, Gideon Welles, and Salmon
Chase. Analysis of the frequently occurring function words involving
principal components analysis show clear discrimination between
writers and internal consistency within writers. The Diary itself also
shows remarkable internal consistency and strongly appears to have
been written by a single person.
A pioneering use of the new Delta method, proposed recently
by Burrows, was then employed on a wide cast of contenders.
This technique, based on the 100 most frequently occurring
words in the pooled corpus, shows that the closest ``match'' to
the Diary is indeed Hurlbert, followed by Ward. Attention then
focuses on these two contenders only. For the attributional
stage of the analysis, discriminant analysis was employed.
All 12 Diary samples are placed into the Hurlbert group.
The non-traditional stylometric analysis has supplied objective
evidence that supports traditional scholarship regarding the problem
of the authorship of the Diary. The likelihood that the entire
document was written by one person is very strong. William Hurlbert
has been pinpointed, to the exclusion of all others, as the Diarys
author. Much of the Diary could never have been concocted after the
fact; the chances are that the entire document is authentic.
Leanna House and D. Banks, Duke University,
``Cherry-Picking as a Robustness Tool''
Abs:
When there are problems with data quality, it often
happens that a reasonably large fraction is good data, and expresses a
clear statistical signal, while a smaller fraction is bad data that
shows little signal. If it were possible to identify the subset of the
data that collectively expresses a strong signal, then one would have
a robust tool for uncovering structure in problematic datasets.
This paper describes a search strategy for finding large subsets of
data with strong signals. The methodology is illustrated for problems
in regression. This work is part of a
year-long program in statistical data mining that has been organized
by SAMSI, the new National Science Foundation center for research at
the interface of statistics and applied mathematics.
J. Hughes-Oliver, North Carolina State University, ``Twins and
High Dimensional Data: Can Leave-one-out Cross Validation Survive?''
Abs:
High-dimensional low-sample-size problems cause many difficulties for
analysis and interpretation. Leave-one-out cross validation is routinely
recommended as a technique for assessing a model's predictive power
without overfitting. Unfortunately, when the dataset contains virtually
identical cases (which we call twins), leave-one-out cross validation
may give an overly optimistic assessment of a model's predictive power.
Using a recently published study for investigating whether in vitro gene
expression profiles of drug efficacy can predict therapeutic classes of
compounds, we demonstrate the existence of twins and their impact on
several cross-validation studies.
Myung-Hoe Huh, Korea University,
``Enhancing Self-Organizing Maps for Statistical Use''
Abs:
Self-organizing map (SOM) is an unsupervised learning neural network
method developed by Teubo Kohonen of Finland and his colleagues since
1980's (Kohonen, 1995). SOM is known to be very useful in pattern
recognition and text information retrieval areas, as demonstrated by
numerous studies (cf. www.cis.hut.fi/research/som-bibl/ and
www.soe.ucsc.edu/NCS). The main virtue of SOM is the
topological ordering property, which enables visualization and
abstraction of data sets at the same time (Kohonen, 1998).
SOM has been neglected in statistical community, because of its
engineering orientation. Only a few years ago, applied
statisticians began to use Kohonen's mapping method in exploratory
analyses of large data sets or data mining. Readable writings are
available now in several statistical text books such as Ripley
(1996) and Hastie, Tibshirani and Friedman (2001).
Statisticians face several problems in applying SOM, as I
experienced in several mining occasions:
1) How to select the size and the shape of SOM appropriate for the
given data set? For instance, which is a better map between 12 4 SOM
and 77 SOM? [These two have nearly same number of nodes, but
different shapes.] If 124 is the choice, is there better one of the
same shape? 2) SOM yields the visual plot of discrete form, which is
not natural to statisticians who expect a visual plot of continuous
type. How to get one without much effort? 3) SOM displays observation
units, but the map is not guided by variables. Consequently, it is not
easy to catch the meaning of SOM intuitively.
4 SOM
and 77 SOM? [These two have nearly same number of nodes, but
different shapes.] If 124 is the choice, is there better one of the
same shape? 2) SOM yields the visual plot of discrete form, which is
not natural to statisticians who expect a visual plot of continuous
type. How to get one without much effort? 3) SOM displays observation
units, but the map is not guided by variables. Consequently, it is not
easy to catch the meaning of SOM intuitively.
Myung-Hoe Huh, Korea University, and Yong-Goo Lee, Chung Ang
University, ``Reproducibility Evaluation of k-Means Clustering''
Abs:
On the K-means clustering, the number of clusters(K) have to be
decided at first. But there are no objective ways to decide the
appropriate number of clusters, and we usually decide it by ad hoc
trial. We propose a reproducibility assessment procedure of K-means
cluster analysis by randomly partitioning the data set into three
parts, of which two subsets are used for developing clustering rules
and one subset for testing consistency of the rules. Based on the
results of the consistency measure between two clustering rules, we
can determine the number of clusters in K-means clustering. For
measuring the consistency between two clustering rules, we propose an
entropy-based method as an alternative to Rand Index and corrected
Rand Index that have been widely used for measuring the consistency.
Krzysztof Jajuga, ``Data Analysis and Financial Risk
Management: Overview of Modern Approaches''
Abs:
Financial risk management is one of the areas, which gained
considerable importance in last decade. Here the application of
data analysis methods has the significant influence. In this paper we
give very synthetic and systematic survey of the main approaches
used in financial risk analysis. We concentrate on two main types of
risk, namely market risk and credit risk.
The methods developed for risk analysis emerged independently
in two fields: econometrics, where the main notion applied is stochastic
process; and statistics, where the main notion applied is statistical
distribution. In the paper we make attempt to integrate these two fields,
by putting most approaches in the framework of multivariate statistical
distribution derived under the data structure consisting of multivariate
time series.
We use this framework to integrate the methods derived in financial
econometrics, like GARCH models, and modern statistics, like Extreme
Value Theory and copula analysis. It will be shown that this unified
framework encompasses most risk analysis methods proposed by theoreticians
and financial practitioners. We also discuss some other approaches derived in
the theory of finance, where the calibration of the models is done by data
analysis methods.
Maojin Jiang, Eric Jensen, Steve Beitzel, and Shlomo Argamon,
Illinois Institute of Technology, ``Choosing the Right Bigrams for
Information Retrieval''
Abs:
After more than 30 years of research in information retrieval, the dominant
paradigm remains the ``bag-of-words,'' in which query terms are considered
independent of their coocurrences with each other. Although there has been
some work on incorporating phrases or other syntactic information into IR,
such attempts have given modest and inconsistent improvements, at best.
This paper is a first step at investigating more deeply the question of using
bigrams for information retrieval. Our results indicate that only certain
kinds of bigrams are likely to aid retrieval. We used linear regression
methods on data from TREC 6, 7, and 8 to identify which bigrams are able
to help retrieval at all. Our characterization was then tested through
retrieval experiments using our information retrieval engine, AIRE, which
implements many standard ranking functions and retrieval utilities.
David Johannsen and Jeff Solka, Naval Surface Warfare Center,
``Modern Geometric Methods for Dimensionality Reduction''
Abs:
This talk will discuss some of our recent work in the discovery of
2-manifolds within 3-dimensional data sets. Our approach is predicated on
first extracting a simplicial complex representation of the data using the
method of Dey. Given this simplicial complex representation of the data
one can then compute the genus of the underlying manifold via Euler's
equation.
The genus, together with the classification of closed and
orientable 2-manifolds, allows us to endow the simplicial complex with a
homogeneous and isotropic metric.
The original observations can then be projected into this space and this
more
appropriate metric can be used for subsequent cluster or discriminant
analysis.
Karen Kafadar, University of Colorado at Denver, and  Cliff
Speigelman, Texas A&M University,
``Forensic Analyis of Bullet Data''
Abs:
Since the 1960s, FBI has performed Compositional Analysis of Bullet
Lead (CABL), a forensic technique that compares the elemental composition of
bullets found at a crime scene to that of bullets found in a suspect's
possession. CABL has been used when no gun is recovered, or when bullets are
too small or fragmented to compare striations on the casings with those on
the gun barrel.
The National Academy of Sciences formed a Committee charged with the
assessment of CABL's scientific validity. The report, ``Forensic Analysis:
Weighing Bullet Lead Evidence'' (National Research Council, 2004), included
discussions on the effects of the manufacturing process on the validity of
the comparisons, the precision and accuracy of the chemical measurement
technique, and the statistical methodology used to compare two bullets and
test for a ``match''. This talk will focus on the statistical analysis: the
FBI's methods of testing for a ``match'', the apparent false positive and
false negative rates, the FBI's clustering algorithm (``chaining''), and the
Committee's recommendations. Finally, additional analyses on data made
available for future studies will be discussed.
Cliff
Speigelman, Texas A&M University,
``Forensic Analyis of Bullet Data''
Abs:
Since the 1960s, FBI has performed Compositional Analysis of Bullet
Lead (CABL), a forensic technique that compares the elemental composition of
bullets found at a crime scene to that of bullets found in a suspect's
possession. CABL has been used when no gun is recovered, or when bullets are
too small or fragmented to compare striations on the casings with those on
the gun barrel.
The National Academy of Sciences formed a Committee charged with the
assessment of CABL's scientific validity. The report, ``Forensic Analysis:
Weighing Bullet Lead Evidence'' (National Research Council, 2004), included
discussions on the effects of the manufacturing process on the validity of
the comparisons, the precision and accuracy of the chemical measurement
technique, and the statistical methodology used to compare two bullets and
test for a ``match''. This talk will focus on the statistical analysis: the
FBI's methods of testing for a ``match'', the apparent false positive and
false negative rates, the FBI's clustering algorithm (``chaining''), and the
Committee's recommendations. Finally, additional analyses on data made
available for future studies will be discussed.
Tony Kearsley and Luis Melara, National Institute of
Standards and Technology,
``Nonlinear Programming and Multi-Dimensional Scaling''
Abs:
In this presentation, a numerical method for
approximating the solution of specific multidimensional scaling
problems is presented. These problems arise in the analysis of
data such as those produced by nuclear magnetic resonance (NMR)
machinery. The procedure seeks to find a set of n points
in a p-dimensional Euclidean space which minimizes the
proximity of a distance matrix and a predistance matrix.
The presented approach constructs an embedding of the problem
into a higher dimensional space and follows a homotopy path to
the lower p-dimensional space. The optimization can be performed
using less expensive quasi-Newton methods or more expensive
Newton methods. The presentation will conclude with numerical
results of a computationally efficient Gauss-Newton procedure
which is matrix free.
Balaji Krishnapuram, Duke University,
``Autonomous Learning of Multi-Sensor Classifiers''
Abs:
We present an adaptive classifier-learning algorithm that fuses information
(features) from multiple types of sensors. The proposed methods are adaptive
in the sense that they automatically decide what additional information
should be collected in order to optimally improve the accuracy of the
classifier, under the constraints of a limited data-acquisition budget.
Experimental results on measured radar and hyper-spectral image data attest
to the efficacy of the proposed methods in improving the accuracy of the
learned classifier.
Koji Kurihara, Okayama University, ``Classification of
Geospatial Lattice Data and Their
Graphical Representation''
Abs:
Statistical analyses for spatial data are
important problems in various types of fields. Lattice data are
synoptic observations covering an entire spatial region, like cancer
rates broken out by each county in a state. There are few approaches
for cluster analysis of spatial data. But echelons are useful
techniques to study the topological structure of such spatial data.
In this paper, we explore cluster analysis for geospatial lattice
data based on echelon analysis. We also provide new definitions of
the neighbors and
families of spatial data in order to support the clustering procedure. In
addition, the spatial cluster structure is demonstrated by hierarchical
graphical representation with several examples. Regional features are
also shown in this dendrogram.
Katarzyna Kuziak, Wroclaw University of Economics,
``Evaluation of Risk in the Index Option Pricing Model''
Abs:
In the finance theory many mathematical models are used to
value securities or to manage risk. These models are not perfect and
they are subject to many errors, for example these coming from: incorrect
model of price dynamics, using of indirect input parameters in the
estimation, improper implementation of theoretical models, misunderstanding
of relationship between assets in multi-asset derivatives.
Most financial models are derived under the assumption of the existence of
perfect and efficient capital market, but in practice markets are not perfect
and not efficient. This causes the additional risk, a so called model risk. To
avoid this type of risk in some cases, appropriate data analysis
methods can be
used (e.g. robust estimation procedures, distribution analysis, forecasting
techniques).
The purpose of this paper is to evaluate existence of risk in index option
pricing model. Some different models of asset price dynamics will be
considered.
Using different models to value the same option, would yield different option
prices. The paper will present how sensitive option pricing model is to the
assumption about price dynamics. Empirical evidence for index option listed
on Warsaw Stock Exchange will be given.
Vicki Laidler, Computer Sciences Corporation, Space
Telescope Science Institute,
``A Tale of Two
Probabilities: Assessing Accuracy on Classified Astronomical Data''
Abs:
I will explore the use of conditional probabilities, together with a
priori domain knowledge, to understand the reliability of classified
data sets such as astronomical catalogs that label objects as stars or
galaxies. Complications that affect the general problem (such as
minority populations and contamination) will be considered, as well as
those more specific to astronomical observations (such as incompleteness
and blending).
Michael D. Larsen, Iowa State University,
``Issues in Record Linkage''
Abs:
Record linkage is the process of combining information about
individuals or entities across databases. In order to conduct a
statistical analysis, one often has to combine information on people
or units from various sources. Considering the possibility of
terrorist threats, record linkage takes on additional significance -
it might be possible to link databases to determine if the collective
behavior of individuals or entities suggests suspicious or threatening
activities. The use of record linkage in counterterrorism efforts
will involve linking together certain administrative records and
possibly commercial files on the population and interpreting the
results in an effort to identify potentially dangerous or suspicious
occurrences. In the United States, the Department of Homeland
Security (DHS), the Defense Advanced Research Projects Agency (DARPA),
and other agencies are interested in record linkage as part of their
counterterrorism efforts. This talk will review probabilistic record
linkage methods, discuss new advances, and comment on difficulties and
dangers that will be encountered when using these and other methods
for purposes of counterterrorism.
Nicole Lazar, Carnegie Mellon University,
``Are All fMRI Subjects Created Equal?''
Abs:
Group maps created from individual functional neuroimaging maps
provide useful summaries of patterns of brain activation. Different
methods for combining information have been proposed over the years
in the statistical literature; we have recently applied some of these
methods to functional MRI data. The resultant group maps are
statistics, hence it is natural to ask how sensitive they are to the
effects of unusual subjects. "Unusual" here might be in terms of
extent, location or strength of activation. In this talk, I consider
a jackknife approach to assessing the influence of individual
subjects on group inferences from an fMRI study. This approach not
only helps users to understand the different effects that subjects
have on the combined data, but also to evaluate the sensitivity of
the different combining methods themselves.
Ludovic Lebart, ENST,
``Validation Techniques for Correspondence Analysis''
Abs:
Correspondence Analysis (CA) techniques play a major role in the
computerized exploration of categorical data. It provides useful
visualizations (e.g. in socio-economic surveys, in marketing)
highlighting associations and patterns between two or more categorical
variables.
Chikio Hayashi is recognized as one of the main discoverer of CA,
which is known also as Hayashi quantification method number 3 ever
since his seminal paper of 1956.
Another pioneering work of Professor Hayashi concerns the early
applications of multidimensional methods, including CA, to a wide
range of national and multinational sample surveys (see: Hayashi,
1987). Several decades ago, his general conception of applied
multivariate statistics, coined later by himself ``Data Science'', was
almost identical to the modern fields of Data Mining and Visualization
Techniques.
However, most of the outputs of these ``unsupervised procedures''
(parameters, graphical displays) still remain difficult to assess.
We will then focus on the two following complementary issues:
- External validation, involving external data or meta-data (generally
considered as supplementary or illustrative elements) and allowing for
classical statistical tests, often involving multiple comparisons
problems.
- Internal validation, based on re-sampling techniques such as
bootstrap and its variants, allowing for systematically enriching the
scattering diagrams on the principal axes with confidence
areas. Validation techniques are particularly complex in the case of
eigenvalues and eigenvectors problem, and the bootstrap appears to be
the only method that provides feasible and efficient procedures.
The data set serving as an example is the British section of a
multinational survey conducted in seven countries (Japan, France,
Germany, Italy, Nederland, United Kingdom, USA) in the late nineteen
eighties (Hayashi et al., 1992).
Re-sampling techniques (mainly bootstrap in the case of unsupervised
approaches) possess all the required properties to provide the user
with the versatile tools that transform appealing visualizations into
scientific documents.
Bruno Leclerc, EHESS, ``The Consensus of Classification Systems, with
Adams' Results Revisited''
Abs:
The problem of aggregating a profile of closure systems into a
consensus closure system has interesting applications in
classification. We first present an overview of the results
obtained by a lattice approach. Then, we develop a more refined
approach based on overhangings and implications that appears to be
a generalization of Adams' consensus tree algorithm.
Adams' uniqueness result is explained and generalized.
Herbert K. H. Lee, University of Santa Cruz, ``Priors for Neural
Networks''
Abs:
Neural networks are commonly used for classification and regression.
The Bayesian approach may be employed, but choosing a prior for the
parameters presents challenges. This paper reviews several priors in
the literature and introduces Jeffreys priors for neural network
models. The effect on the posterior is demonstrated through an
example.
Seong Keon Lee, Chuo University,
``On Classification and Regression Trees with Multiple
Responses''
Abs:
The tree method can be extended to multivariate responses, such as
repeated measures and longitudinal data, by modifying the split
function so as to accommodate multiple responses. Recently, some
decision trees for multiple responses have been constructed by other
researchers. However, their methods have limitations on the type of
response, that is, they allow only continuous or only binary responses.
Also, there is no tree
method to analyze polytomous and ordinal responses.
In this paper, we will modify the tree for the univariate response
procedure and suggest a new tree-based method that can analyze any
type of multiple response by using Generalized Estimating
Equations (GEE) techniques.
Sun-Soon Lee, Seoul National University, Hong-Seok Lee, Sung
Kyun Kwan University, Joong-Hwan Lee, Needs I Co. Ltd., and Sung-Soo
Kim, Korea National Open University, ``Customer Segmentation using
gCRM''
Abs:
gCRM(geographical Customer Relationship Management) is an integrated
solution of GIS(Geographic Information System) and CRM(Customer
Relationship Management). It is Territory Market Customer Relation
Management that includes database system of GIS and CRM. gCRM uses GIS
technique to show one or multi dimensional analytical result of
customer information. gCRM technique is being improved by using the
space data mining, a satellite location confirmation system (Global
Positioning System), the PDA and mobile phone techniques.
In this research, we introduce gCRM combined with Life Style
Information. This system can be efficiently used for customer
segmentation graphically. Especially the interactive visualization of
clustered customer groups using gCRM can be powerfully used for
customer segmentation in marketing.
Taerim Lee, Korea National Open University,
``A Tree-Structured Survival Model for AIDS in Korea''
Abs: TBA
Mohamed Mehdi Limam and Edwin
Diday, University of Paris IX-Dauphine, and Suzanne Winsberg,
Institut de Recherche et Coordination Acoustique/Musique,
``Probabilistic Allocation of Aggregated Statistical Units in
Classification Trees for Symbolic Class Description''
Abs:
Consider a class of statistical units, in which each unit may be an aggregate
of individual statistical units. Each unit is decribed by an interval of
values for each variable. Our aim is to develop a partition of this class
of aggregated statistical units in which each part of the
partition is described by a conjunction of characteristic properties. We use
a stepwise top-down binary tree method and we introduce a probabilistic
approach to assign units to the nodes of the tree. At each step we select the
best variable and its best split to optimize simultaneously a
discrimination criterion given by a prior partition and a homogeneity
criterion. Finally, we present an example of real data.
Xiaodong Lin, SAMSI, and Yu
Zhu, Purdue University,
``Degenerate Expectation-Maximization Algorithm for Local Dimension
Reduction''
Abs:
Dimension reduction techniques based on principal component
analysis (PCA) and factor analysis are commonly used in
statistical data analysis. The effectiveness of these methods is
limited by their global nature. Recent efforts have focused on
relaxing global restrictions in order to identify subsets of data
that are concentrated on lower dimensional subspaces. In this
paper, we propose an adaptive local dimension reduction method,
called the Degenerate Expectation-Maximization Algorithm (DEM).
This method is based on the finite mixture model. We demonstrate
that the DEM yields significantly better results than the local
PCA (LPCA) and other related methods in a variety of synthetic and
real datasets. The DEM algorithm can be used in various
applications ranging from clustering to information retrieval.
Regina Liu, Rutgers University, ``Mining Massive Text Data and
Developing Tracking Statistics''
Abs:
This paper outlines a systematic data mining procedure for exploring
large free-style text datasets to discover useful features and
develop tracking statistics, generally referred to as performance
measures or risk indicators. The procedure includes text mining,
risk analysis, classification for error measurements and
nonparametric multivariate analysis. Two aviation
safety report repositories PTRS from the FAA and AAS from
the NTSB will be used
to illustrate applications of our research to aviation risk
management and general decision-support systems. Some specific
text analysis methodologies and tracking statistics will be discussed.
Approaches to incorporating misclassified data or error measurements
into tracking statistics will be discussed as well.
Hermann Locarek-Junge, Dresden University of Technology,
``Estimation of Tail Coefficients
and Extreme Correlations for Market and Credit Risk: Problems,
Pitfalls, and Possible Solutions''
Abs:
Value-at-Risk (VaR) is a well known risk measurement concept. It has
its special problems, however. A new concept for market risk
measurement is conditional VaR (CVaR), which has its own problems. To
estimate probabilities from historical data, it is necessary to
address the problem of extreme correlation and for credit risk -
correlated defaults. First estimators are discussed in the framework
of a Bernoulli-mixture model, and second for the single-factor model
known from Basel II, the maximum-likelihood estimators are given.
Analogously to rating classes homogeneous groups of obligors are
considered.
Vincent Loonis, ENSAE,
``The Simultaneous Row and Column Partitioning of Several
Contingency Tables''
Abs:
This paper focuses on the simultaneous aggregation of
modalities for more than two categorical variables. I propose to
maximize an objective function closely similar to the criteria used in
multivariate analysis. The algorithm I suggest is a greedy process
which, at each step, merges the two most criterion-improving items in
the nomenclature. As the solution is only quasi-optimal, I
present a consolidation algorithm to improve on this solution, for a
given number of clusters.
Carlos Lourenço and Margarida Cardoso, ISCTE,
``Market Segmentation: A Comparison Between Mixture Models and Data
Mining Techniques''
Abs:
While many of both marketing research scientists and marketers are
still segmenting markets by means of nonoverlapping and overlapping
methods, two distinct approaches are competing for a place in the
segmentation methods podium: probabilistic methods and data mining
techniques. With the clear advantage of allowing for statistical
inference, probabilistic methods provide some of the most powerful
algorithms for market segmentation. However, data mining techniques
are increasingly applied to market segmentation and trying to overcome
the accusation of lack of statistical properties.
Using recent computational developments and the same data, we compare
the estimation of mixture models with two data mining techniques: the
TwoStep method (based on the BIRCH clustering method) and Kohonen
neural networks to build up a SOM.
We extensively explore different (and appropriate) parameterizations
on the referred methods and analyse their performance. We suggest some
methodologies of evaluation and characterization of segments'
structures for the methods used.
Guanzhong Luo and David Andrich, Murdoch University, ``The Weighted
Likelihood Estimation of
Person Locations in an Unfolding Model for Polytomous Responses''
Abs:
It is well known that there are no meaningful sufficient statistics for
the person locations in a single peaked unfolding response model. The
bias in the estimates of person locations of the general unfolding
model for polytomous responses (Luo 2001) with conventional Maximum
Likelihood Estimation (MLE) is likely to accumulate with various
algorithms proposed in the literature. With the main aim of preventing
the bias in the estimates of person locations in the equi-distant
unfolding model when the values of item parameters are given, this
paper derives the Weighted Likelihood Estimation (WLE) equations,
following the approach of Warm (1989). A preliminary simulation study
is also included.
Vladimir Makarenkov, Alix Boc, and Abdoulaye Baniré
Diallo, University of Quebec,
``Determining Horizontal Gene Transfers in Species Classification:
Unique Scenario''
Abs:
The problem of species classification, taking into
account the mechanisms of reticulate evolution such as
horizontal gene transfer (HGT), species hybridization,or gene
duplication, is very delicate.
In this paper, we describe a new algorithm
for determining a unique scenario of HGT events in a given additive
tree (i.e., a phylogenetic tree) representing the evolution of a group of
species.
The algorithm first establishes differences between topologies of
species and gene-additive trees. Then it uses
a least-squares optimization procedure to test for the possibility
of horizontal gene transfers between any pair of edges of the species
in the tree, considering all previously added HGTs in order to
determine the next one.
We show how the proposed algorithm
can be used to represent possible ways in which
the rubisco 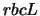 gene has spread in a species classification that
includes plastids, cyanobacteria, and proteobacteria.
gene has spread in a species classification that
includes plastids, cyanobacteria, and proteobacteria.
David Marchette, Naval Surface Warfare Center,
``Iterative Denoising for Cross-Corpus Discovery''
Abs:
Given two disparate corpora
we wish to identify meaningful cross-corpus associations;
e.g., observations in different corpora
satisfying, perhaps, a dictionary definition of serendipity:
a meaningful discovery not explicitly sought.
Toward this end,
we introduce an iterative denoising methodology for cross-corpus
discovery. This is a method for dimensionality reduction and
search that utilizes corpus-dependent projections.
We take a (perhaps overly) broad definition of corpus; we will
illustrate the methodology on hyperspectral data
analysis, text document processing, and analyzing
user login sessions.
M. Markatou, H. Tian, S. Biswas, and G. Hripsack,
Columbia University, ``Analysis of the Effect
of Correlation on the Cross-Validation Estimates of the Performance of
Learning Algorithms''
Abs:
We address the problem of estimating the variance of cross-validation
estimates of the generalization error. For cross-validation based on
random sampling of training and test sets, we show that the variability
induced by different training and test sets can be quantified by the
expectation of two random variables. One is the random variable that
expresses the cardinality between the intersection of two different
training sets, the other denotes the cardinality of the intersection
between the corresponding test sets. We provide moment approximations of
the cross-validation statistic that estimates the generlization error. The
moment approximations are then used to analyze the variance of the
CV-estimator. The case of non-overlapping test sets is obtained as a
special case of the derived results.
Paul Marriott, University of Waterloo,
``On the Geometry of Mixtures''
Abs:
The class of statistical models known as mixtures have wide
applicability in applied problems due to their flexibility,
naturalness and interpretability. However despite their apparent
simplicity the inference problem associated with them remains hard,
both from a theoretical and a practical standpoint. This talk gives
an overview of some methods which use geometric techniques to
understand the problem of inference under mixture models. The recently
introduced class of local mixtures is shown to have many
applications, managing to retain a great deal of flexibility and
interpretability while having excellent inference
properties. Throughout this talk technical issues will be kept to a
minimum and a visual and graphical approach will be taken when
explaining both statistical and geometric ideas.
Chérif Mballo, ESIEA, and Edwin Diday, University of
Paris-Dauphine IX, ``Kolmogorov-Smirnov for Decision
Trees on Interval and Histogram Variables''
Abs:
With advances in technology, data sets often
contain a very large number of observations. Symbolic data
analysis treats new units that are underlying concepts of the
given data base or that are found by clustering. In this way, it is
possible to reduce the size of the data to be treated by
transforming the initial classical variables into variables called
symbolic variables. In symbolic data analysis, we consider, among
other types, interval and histogram variables. The algebraic
structure of these variables leads us to adapt dissimilarity
measures to be able to study them. The Kolmogorov-Smirnov criterion is
used as a test selection metric for decision tree induction. Our
contribution in this paper is to adapt this criterion of
Kolmogorov-Smirnov to these types of variables. We present an
example to illustrate this approach.
Masahiro Mizuta, Hokkaido University, ``Relative Projection
Pursuit and Its Applications''
Abs:
In this paper, we propose a new
method of projection pursuit, relative projection pursuit (RPP),
which finds `interesting' low dimensional spaces different from
reference data sets predefined by the user.
In addition, as an application of the method, we develop a
new dimension reduction method: sliced inverse regression
with relative projection pursuit.
Recently, high dimensional datasets
such as microarray gene data and point-of-sale data have become important.
It is generally difficult to see the structure of data when the
dimension of data is high.
Therefore, many studies have invented
methods that reduce high dimensional data to lower dimensional
data.
Among these methods, projection pursuit was developed by
Friedman and Tukey (1974) in order to search for an `interesting'
linear projection of multidimensional data.
They defined the
degree of `interestingness' as the difference between the
distribution of the projected data and the normal distribution.
We call this measure a projection index.
However, projection
indices that measure the difference from the normal distribution
do not always reveal interesting
structure because interesting
structure depends on the purpose of the analysis.
According to the scientific
situation that motivates the data analysis,
`uninteresting' structure is not
always the normal distribution.
Relative projection pursuit allows the user
to predefine a reference data set that represents `uninteresting'
structure.
The projection index for relative projection pursuit measures
the distance between the distribution of the projected target data set
and that of the projected reference data set.
We show the effectiveness of RPP with numerical examples and actual
data.
Takashi Murakami, Nagoya University,
``The Direct Procrustes Method and Perfect Congruence''
Abs:
The direct procrustes method is a procedure to obtain a set of
orthonormal composites of variables whose pattern is closest to a
specified target matrix in the least-squares sense (Murakami,
2000). Derivation of a set of oblique composites whose pattern is
perfectly congruent to any target is always possible as was proven by
Ten Berge (1986). One may also define a set of composites by the use
of elements of the target as weights. Sets of composites obtained from
a real data by these methods were compared empirically in terms of the
amount of explained variance, the congruence of the pattern to the
target, and the similarity between the pattern and the matrix of
weights. Extensions of direct procrustes method to the oblique case
were examined as well. Principal components and their (orthogonal and
oblique) procrustes rotation were used as reference points for the
comparisons. The results shows that the group centroid method and its
minimally orthonormalized (Johnson, 1966) version based on the simple
sums of specified sets of variables generally produced most desirable
solution as long as the target has the form of very simple structure.
Fionn Murtagh, Queen's University Belfast, ``Thinking
Ultrametrically''
Abs:
The triangular inequality is a defining property of a metric space,
while the stronger ultrametric inequality is a defining property of an
ultrametric space. Ultrametric distance is defined from p-adic
valuation.
It is known that ultrametricity is a natural property of spaces
that are sparse. Here we look at the quantification of ultrametricity.
We also look at data compression based on a new ultrametric wavelet
transform. We conclude with computational implications of
prevalent and perhaps ubiquitous ultrametricity.
Mohamed Nadif, Université de Metz, and Gérard
Govaert, Université de Technologie de Compiègne, ``Another
Version of the Block EM Algorithm''
Abs:
While most clustering procedures aim to construct an
optimal partition of objects or, sometimes, of variables, there are
other methods, called block clustering
methods, which consider simultaneously the two sets and organize the
data into homogeneous blocks.
Recently, we have proposed a new mixture model called a
block mixture model that addresses this situation.
Our model allows one to embed simultaneous clustering of
objects and variables through a mixture approach.
We use maximum likelihood (ML) to implement the method, and have
developed a new EM algorithm
to estimate the parameters of this model.
This requires an approximation of the likelihood and we
propose an alternating-optimization algorithm, which is compared to
another version of EM based on an
interpretation given by Neal and Hinton.
The comparison is
performed through numerical experiments on simulated binary data.
Jeremy Nadolski and Kert Viele, University of Kentucky,
``The Role of Latent Variables in Model Selection Accuracy''
Abs:
Mixture models are often formulated in terms of latent variables Z which
determine the component membership of the observations. While these
latent variables are often used solely as a computational tool, we will
discuss how the latent variable formulation provides insight into model
selection procedures. We will demonstrate conditions on the latent
variables that cause BIC (and other model selection procedures) to fail,
and suggest alternative methods for model selection more suited for
those conditions.
Seungmin Nam, Kiwoong Kim, and Sinsup Cho, Seoul National
University, and Inkwon Yeo, Chonbuk National University,
``A Bayesian Analysis Based on Beta-Mixtures for Software Reliability
Models''
Abs:
Nonhomogeneous Poisson Process is often used to model failure times
occurred in software reliability and hardware reliability models. It
can be characterized by its intensity functions or mean value
functions. Many parametric intensity models have been proposed to
account for the failure mechanism in real situation. In this paper, we
propose a Bayesian semiparametric approach based on beta-mixtures. Two
real datasets are analyzed.
Tom Nichols, University of Michigan, ``Detecting a Conjunction of Alternatives:
Finding Consistent Activations in Functional Neuroimaging Data using FDR''
Abs:
Detecting a Conjunction of Alternatives: Finding Consistent
Activations in Functional Neuroimaging Data using FDR
Psychologists studying memory use Functional Magnetic Resonance
Imaging (fMRI) to understand how information is encoded, stored and
retrieved in the brain. Short term, or working memory, can be
'probed' in a number of ways, say by asking a subject to remember a
list of words, or a list of digits, or even even a collection of
shapes (triangles, squares, etc). The goal is to identify regions of
the brain that support working memory generically, but which are not
specialized to words or numbers or shapes. This requires testing a
union of nulls (no effect in one or more of the three tasks) versus an
intersection of alternatives (effects in all three tasks).
Worsley and Friston proposed using the maximum P-value to test for a
intersection of effects, but their inference is based on the
intersection of nulls. This is problematic, as a rejection of the
intersection null is just the union of alternatives, and not the
psychologist's desired "conjunction". We show that a simple approach
does allow 'Conjunction Inference' using the minimum statistic.
Further, we propose using Storey's Positive False Discovery Rate
(pFDR) to make inference on the union of nulls. Storey shows that
pFDR can be interpreted as the posterior probability of the null given
that a statistic lies in a rejection region. Our method can
approximately be seen as making inference on the sum of q-values. We
demonstrate the method on simulated and real data.
Ole Nordhoff, Institut für Statistik und
Wirtschaftsmathematik,
``Expectation of Random Sets and the `Mean Values' of Interval Data''
Abs:
Clustering methods often use class representatives or prototypes
to describe data clusters. Prototypes are involved in many clustering criteria,
where the dissimilarity between a data point and a cluster
representative is considered.
Moreover, the properties of a cluster are often characterized briefly
by one single data
point, e.g., the class centroid.
When one clusters 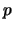 -dimensional interval data
-dimensional interval data
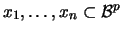 (rectangles in
(rectangles in
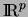 ) with a certain clustering
method one is searching for `mean value of intervals' in
) with a certain clustering
method one is searching for `mean value of intervals' in 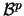 as
a prototype
of data in a class. This paper deals with the question how the mean of some
-dimensional intervals can be defined. We will introduce two different ways
for defining the mean of
(-dimensional) intervals. The first approach is to reduce an interval to
its 'lower left' and 'upper right vertex' and shift
the problem to the case of real-valued
data points, where the definition of expectation and mean is well
known. In the second approach we consider an interval as a special
form of a closed (convex) set and utilise the theory of Random Closed
Sets (RCSs) to define the mean via definitions of
expectation. This approach is influenced by papers of Molchanov
and Stoyan.
There are a couple of different definitions, each of them with
special properties. We pick out three definitions, illustrate them by
examples and check for an extract of axiomatic properties, if they are
fulfilled
or not. Finally, we will discover that in some cases different definitions of
`expectation' are equal, if the considered sets are intervals.
as
a prototype
of data in a class. This paper deals with the question how the mean of some
-dimensional intervals can be defined. We will introduce two different ways
for defining the mean of
(-dimensional) intervals. The first approach is to reduce an interval to
its 'lower left' and 'upper right vertex' and shift
the problem to the case of real-valued
data points, where the definition of expectation and mean is well
known. In the second approach we consider an interval as a special
form of a closed (convex) set and utilise the theory of Random Closed
Sets (RCSs) to define the mean via definitions of
expectation. This approach is influenced by papers of Molchanov
and Stoyan.
There are a couple of different definitions, each of them with
special properties. We pick out three definitions, illustrate them by
examples and check for an extract of axiomatic properties, if they are
fulfilled
or not. Finally, we will discover that in some cases different definitions of
`expectation' are equal, if the considered sets are intervals.
Hodaka Numasaki, Hajime Harauchi, Yuko Ohno, Osaka
University, Kiyonari Inamura, Kansi University of International
Studies, Satoko Kasahara, Morito Monden, and Masato Sakon, Osaka
University,
``Application of Spectrum Analysis and Sequence Relational Analysis
for the Medical Staff's Job Classification: Use of Time Factor and
Behavior Factors for Job Workflow''
Abs:
Object: To investigate the efficient job workflow, the occurrence order
and frequency of the job elements and the relation between the job
elements are the important information. In this research, new
methodology of job classification was proposed from the viewpoint of
periodicity and relationship among job elements.
Method: The periodicity and the incident condition of job elements were
analyzed by the discrete Fourier transformation on the time-series
occurrence information of the time-motion study data. The strength of
the relation among the job-sequence was investigated by the sequence
relational analysis.
Data: A series of 24 hr time-motion studies for the medical staff at a
surgical ward was carried out from 1998 to 2001, and a total of 23 days
of job was observed and recorded.
Results: All job elements of the ward were classified into five incident
patterns based on the periodicity of each element [emergent, routine,
time-dependent, arbitrary-provided and mixed] and into three patterns
based on the association with other jobs [independent, interdependent
with other jobs and random]. Using this classification framework, a
total of 250 job elements were clearly categorized and the job-workflow
patterns of medical staff were clarified.
Next: Abstracts O-Z
Up: abstracts
Previous: Abstracts A-D