

Next: Abstracts E-N
Up: abstracts
Previous: abstracts
Rafik Abdesselam, Université de Caen Basse-Normandie,
``Sequential Multiple Discriminant Analysis''
Abs:
A sequential discriminant analysis method of evolutionary data classifying
aim is described. This method of decision-making is based on the
research of principal
axes of a configuration of points in the individual-space with a
relational distance. We
are in presence of a discriminant analysis problem, in which the
decision must be taken as
the partial knowledge evolutionary information of the observations of
the statistical unit,
which we want to classify. The constraint consists in imposing to the
discriminant factors
to be part of the subspace associated to all the observations carried
out during this partial
period. The sequential analysis proposed consist to make a relational
multiple discriminant analysis of the global explanatory configuration
of points, corresponding to all the
observations carried out during the global period, projected on the
partial subspace. We
thus show how what the knowledge from the observation of the global
testimony sample
carried out during the entire period, can benefit to the classifying
decision on supplementary statistical units, which we only have
partial information about. This sequential
discriminant analysis is a simple method which can be very useful
particularly in the
medical field for diagnosis-making, where it is often important to
anticipate before term
to be able to intervene in time if necessary. An analysis using real
data is here described
using this method.
Edgar Acuña and Caroline Rodriguez, University of Puerto
Rico, ``The Treatment of Missing
Values and Its Effect on Classifier Accuracy''
Abs:
The presence of missing values in a dataset
can affect the performance of a classifier constructed using that
dataset as a training sample. Several methods have been proposed
to treat missing data and the one used most frequently deletes
instances containing at least one missing value of a feature. In
this paper we carry out experiments with twelve datasets to
evaluate the effect on the misclassification error rate of four
methods for dealing with missing values: the case deletion method,
mean imputation, median imputation, and the KNN imputation procedure.
The classifiers considered were the Linear Discriminant Analysis
(LDA) and the KNN classifier. The first one is a parametric
classifier whereas the second one is a nonparametric classifier.
Kohei Adachi, Ritsumeikan University,
``An Oblique Procrustes Technique for Simultaneously
Rotating Component and Loading Matrices''
Abs:
Let F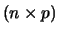 and A
and A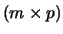 express the component and loading
matrices, respectively, obtained with the principal component
analysis of X
express the component and loading
matrices, respectively, obtained with the principal component
analysis of X 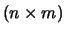 . That is, X* = FA'
= FSS
. That is, X* = FA'
= FSS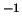 A', where X* is
the matrix of rank
A', where X* is
the matrix of rank 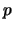 approximating X best and S is
an arbitrary
nonsingular matrix of
approximating X best and S is
an arbitrary
nonsingular matrix of 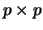 . We consider the problem of
transforming F and A into FS and
AS' so that they match G
(containing target components) and B (target loadings),
respectively, as closely as possible. This problem is formulated
as minimizing
. We consider the problem of
transforming F and A into FS and
AS' so that they match G
(containing target components) and B (target loadings),
respectively, as closely as possible. This problem is formulated
as minimizing
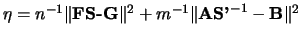 over S. Let
S = K
over S. Let
S = K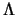 L' define the singular value
decomposition of S with
L' define the singular value
decomposition of S with
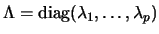 . Then,
. Then, 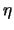 is rewritten as
is rewritten as
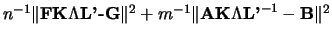 .
For minimizing this, we use an algorithm in which the
following three steps are iterated alternately. First, is
minimized over K subject to K'K=KK'= I (the identity
matrix). Second, is minimized over L under
L'L=LL' = I. Third,
is minimized over
.
For minimizing this, we use an algorithm in which the
following three steps are iterated alternately. First, is
minimized over K subject to K'K=KK'= I (the identity
matrix). Second, is minimized over L under
L'L=LL' = I. Third,
is minimized over 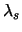 for
for
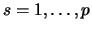 , which is
attained by solving
an quartic equation of . The method is detailed and
illustrated
with numerical examples in the presentation.
, which is
attained by solving
an quartic equation of . The method is detailed and
illustrated
with numerical examples in the presentation.
F. Afonso, University of Paris-Dauphine,
Lynne Billard, University of Georgia, and Edwin Diday, University of
Paris-Dauphine, ``Symbolic Linear
Regression with Taxonomies''
Abs:
This work deals with the extension of classical
linear regression to symbolic data and constitutes a continuation
of previous papers from Billard and Diday on linear regression
with interval and histogram-valued data. In this paper, we present
a method for regression with taxonomic variables. Taxonomic variables are
variables organized in a tree with several levels of generality.
For example, the towns are aggregated up to their regions, the
regions are aggregated up to their country.
Ulas Akkucuk and Doug Carroll, Rutgers University,
``Mapping of Nonlinear Manifolds: ISOMAP and a Version of
PARAMAP''
Abs:
Dimensionality reduction techniques are used for representing higher
dimensional data by a more meaningful lower dimensional structure. In this
paper we will study two such approaches, namely Carroll's Parametric Mapping
(abbreviated PARAMAP) (Shepard & Carroll, 1966) and ISOMAP (Tenenbaum, de
Silva, & Langford, 2000). The former relies on iterative minimization of a
cost function while the latter applies classical MDS after a preprocessing
step involving the use of a shortest path algorithm to define approximate
geodesic distances. We will develop a measure of congruence based on
preservation of local structure between the input data and the mapped low
dimensional embedding, and compare the different approaches on various sets
of data with and without error and irregular spacing of points (in the case
of 62 points on the surface of a closed sphere). We will also improve
PARAMAP to deal with a larger number of data points by devising a method to
split the data into a landmark and a holdout sample, and then extrapolate
the holdout points from the landmark configuration. The former will be
accomplished by using a procedure intended to find an initial seed for the
K-means procedure (DeSarbo, Carroll, Clark, & Green, 1984) and the latter by
applying PARAMAP to map in the holdout points into the lower dimensional
landmark configuration.
Yasumasa Baba and  Noboru Ohsumi, Institute of Statistical Mathematics,
``Chikio Hayashi and Data Science in Japan''
Chikio Hayashi was one of the leading researchers in the field of
statistics and data analysis in Japan and also the pioneer of data
science. Covering a wide range of statistics subjects for half a
century, Hayashi continued to drive the development of data science in
this country, particularly in the area of survey research and data
analysis. Talking about his research achievements is talking about the
progress of data science in Japan. Thus, this paper attempts to trace
the footsteps of his research activities, focusing on his two
important study themes: quantification methods (or named formally as
quantification theory) for qualitative data and survey research.
Hayashi always based his studies on observation of real phenomena
maintaining his distinctive research style of ``from designing the
experiments to analyzing data collected originally.'' A series of
methods for analyzing qualitative data, named by social psychologist
Hiroshi Akuto as Hayashi's quantification method type I, II and so on,
were born out of a need for data analysis in the course of the
professor's pursuit for individual research goals. The first method of
the series was conceived in 1950 when Hayashi was groping for the
procedures to evaluate criminal convicts for their post-release
recidivism possibilities and divide them into two groups in accordance
with resulting risk factors. Hayashi began his study on this subject
in 1947, and in 1950 formulated a method of discriminant analysis
based on multivariate categorical data which was to be named later as
quantification method type II. This was followed by quantification
method type IV (1951) which is now regarded as a kind of MDS
(multidimensional scaling methods), quantification method type I
(1952) which is a kind of multiple regression analysis of qualitative
data, quantification method type III (1956) which is comparable to
correspondence analysis proposed by Benzécri in 1960s, and so on.
Placing a particular emphasis on sample survey, Hayashi
conducted researches in a wide range of fields. His broad
interest included such areas of marketing research, social
survey research, and animal population assessment. In the late
1940s, Hayashi studied sample survey theory with his
colleagues, and applied it to social survey. In 1953, the
Institute of Statistical Mathematics (ISM) initiated a
five-year interval sample survey project to study the Japanese
national character. Hayashi, who played a leader in the
initial project designing, has remained one of the project
leaders until 1998. This project is now regarded that was
contributing to the establishment of sample survey methods in
Japan, and hence Hayashi is admired as the key person who
enabled it to happen.
Advancing his survey methodologies with interests extended to the
field of international comparative survey, Hayashi was lately working
on analysis of the national character of a nation by extracting its
features from the findings of social surveys carried out there. One
fruit born out his efforts was CLA (cultural link analysis), the
cross-national studies to alternatively cast a distinctive light on
the relationship among the Americans, the Japanese and
Japanese-American people who embody culture of the both
countries. Hayashi was proposing that this approach is applied to
compare among other counties in Asia and Europe as the means to
interpret complicated interrelations among many nations. After his
death, his successors are continuing to advance his achievements in
these studies. In advocating data science, Hayashi of late years was
intending to break through traditional statistics and make an effort
to find a new dimension with much broader perspective.
Noboru Ohsumi, Institute of Statistical Mathematics,
``Chikio Hayashi and Data Science in Japan''
Chikio Hayashi was one of the leading researchers in the field of
statistics and data analysis in Japan and also the pioneer of data
science. Covering a wide range of statistics subjects for half a
century, Hayashi continued to drive the development of data science in
this country, particularly in the area of survey research and data
analysis. Talking about his research achievements is talking about the
progress of data science in Japan. Thus, this paper attempts to trace
the footsteps of his research activities, focusing on his two
important study themes: quantification methods (or named formally as
quantification theory) for qualitative data and survey research.
Hayashi always based his studies on observation of real phenomena
maintaining his distinctive research style of ``from designing the
experiments to analyzing data collected originally.'' A series of
methods for analyzing qualitative data, named by social psychologist
Hiroshi Akuto as Hayashi's quantification method type I, II and so on,
were born out of a need for data analysis in the course of the
professor's pursuit for individual research goals. The first method of
the series was conceived in 1950 when Hayashi was groping for the
procedures to evaluate criminal convicts for their post-release
recidivism possibilities and divide them into two groups in accordance
with resulting risk factors. Hayashi began his study on this subject
in 1947, and in 1950 formulated a method of discriminant analysis
based on multivariate categorical data which was to be named later as
quantification method type II. This was followed by quantification
method type IV (1951) which is now regarded as a kind of MDS
(multidimensional scaling methods), quantification method type I
(1952) which is a kind of multiple regression analysis of qualitative
data, quantification method type III (1956) which is comparable to
correspondence analysis proposed by Benzécri in 1960s, and so on.
Placing a particular emphasis on sample survey, Hayashi
conducted researches in a wide range of fields. His broad
interest included such areas of marketing research, social
survey research, and animal population assessment. In the late
1940s, Hayashi studied sample survey theory with his
colleagues, and applied it to social survey. In 1953, the
Institute of Statistical Mathematics (ISM) initiated a
five-year interval sample survey project to study the Japanese
national character. Hayashi, who played a leader in the
initial project designing, has remained one of the project
leaders until 1998. This project is now regarded that was
contributing to the establishment of sample survey methods in
Japan, and hence Hayashi is admired as the key person who
enabled it to happen.
Advancing his survey methodologies with interests extended to the
field of international comparative survey, Hayashi was lately working
on analysis of the national character of a nation by extracting its
features from the findings of social surveys carried out there. One
fruit born out his efforts was CLA (cultural link analysis), the
cross-national studies to alternatively cast a distinctive light on
the relationship among the Americans, the Japanese and
Japanese-American people who embody culture of the both
countries. Hayashi was proposing that this approach is applied to
compare among other counties in Asia and Europe as the means to
interpret complicated interrelations among many nations. After his
death, his successors are continuing to advance his achievements in
these studies. In advocating data science, Hayashi of late years was
intending to break through traditional statistics and make an effort
to find a new dimension with much broader perspective.
Kaddour Bachar, Ecole Supérieure des Sciences Commerciales
d'Angers, and Israël Lerman, University of Rennes 1, ``Fixing
Parameters in the
Constrained Hierarchical Classification Method: Application to
Digital Image Segmentation''
Abs:
We analyse the parameter influence of the
likelihood of the maximal link
criteria family (LLA hierarchical classification method) in the
context of the
CAHCVR algorithm (Classification Ascendante Hiérarchique sous Contrainte de
contiguïté et par agrégation des Voisins Réciproques).
The results are
compared to those obtained with the inertia criterion (Ward) in the context
of digital image segmentation. New strategies concerning multiple
aggregation in the class formation and contiguity notion are positively
evaluated in terms of algorithmic complexity.
Daniel Baier, Brandenburg University of Technology Cottbus,
``Pharmaceutical eDetailing and Market Sementation''
Abs:
More and more pharmaceutical companies consider internet based
technologies for explaining and promoting products as a possible means
to stimulate physicians' prescribing without increasing salesforce
costs (see, e.g., Cap Gemini Ernst & Young (2002), Lerer et
al. (2002)). Various so-called eDetailing technologies such as
one-to-one-conferencing, interactive websites, co-browsing, virtual
detailing or online communities have been proposed, implemented and
tested for this purpose (see, e.g., Baier et al. (2004), Bates et
al. (2002)).
The talk gives an overview on these technologies and discusses
findings on how to use these technologies for which market segments
and for which purposes. Furthermore, am own survey on physicians'
usage of the internet and their accessibility as well as the design
and analysis of a larger virtual detailing campaign in corporation
with a pharmaceutical company are discussed.
Simona Balbi and Emilo Di Meglio, University of Naples,
``Contributions of Textual Data Analysis to Text Retrieval''
Abs:
The aim of this paper is to show how Textual
Data Analysis techniques, developed in Europe under the influence of
the Analyse Multidimensionelle des Données School, can improve
performance of the LSI retrieval method. A first improvement can be
obtained by properly considering the data contained in a lexical
table. LSI is based on Euclidean distance, which is not adequate for frequency
data. By using the chi-squared metric, on which Correspondence Analysis is
based, significant improvements can be achieved. Further improvements
can be obtained by considering external information such as keywords,
authors, etc. Here an approach to text retrieval with external
information based on PLS regression is shown. The suggested strategies
are applied in text retrieval experiments on medical journal
abstracts.
Xinli Bao and Hamparsum Bozdogan, University of Tennessee at
Knoxville, ``Subsetting Kernel Regression Models Using Genetic
Algorithm and the Information Measure of Complexity''
Abs:
In this paper we introduce and develop a computationally feasible
subset selection of best predictor variables with kernel partial least
squares regression (K-PLSR) model in reproducing kernal Hilbert space
(RKHS), using genetic algorithm (GA) and the information-theoretic
measure of complexity (ICOMP) criterion of the estimated
inverse-Fisher information matrix (IFIM) developed by Bozdogan (1988,
1990, 1994, 2000, and 2004).
Jean-Pierre Barthélemy, GET-ENST Bretagne, ``Binary
Clustering and Boolean Dissimilarities''
Abs:
In many clustering systems (hierarchies, pyramids, weak hierarchies)
clusters are generated by two elements only. This talk is devoted to
such clustering systems. It includes three parts.
In the first one the notion of binary clustering is presented and
discussed. In the second relationships between binary clustering and
weak hierarchies is discussed. Finally we introduce a variant of
Melter's boolean metric space, under the name of boolean
dissimilarities, and we establish purely qualitative bijection theorems
between classes of boolean clustering systems and classes of boolean
dissimilarities.
Vladimir Batagelj and Matjaz Zaversnik,
University of Ljubljana, ``Islands, an
Approach to Clustering in Large Networks''
Abs:
In large network analysis we are often interested in important parts
of a given network. There are several ways how to determine them.
In the paper we present a very efficient approach based on the notion
of islands.
Assume that in a given network each vertex has a value measuring
its importance. Let 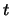 be any real number. If we delete all vertices
(and corresponding edges) with the value less than , we get the
subnetwork called vertex-cut at level . The number and sizes of
its components depend on . Often we consider only components of
size at least
be any real number. If we delete all vertices
(and corresponding edges) with the value less than , we get the
subnetwork called vertex-cut at level . The number and sizes of
its components depend on . Often we consider only components of
size at least 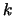 and not exceeding
and not exceeding 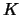 . The components of size smaller
than are discarded as noninteresting while the components of size
larger than are cut again at some higher level.
A vertex-island is a connected subnetwork whose vertices have greater
values than the vertices in its neighborhood. It is easy
to see that the components of vertex-cuts are all vertex-islands.
We developed an algorithm that identifies all maximal vertex-islands
of sizes in the interval
. The components of size smaller
than are discarded as noninteresting while the components of size
larger than are cut again at some higher level.
A vertex-island is a connected subnetwork whose vertices have greater
values than the vertices in its neighborhood. It is easy
to see that the components of vertex-cuts are all vertex-islands.
We developed an algorithm that identifies all maximal vertex-islands
of sizes in the interval 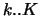 in a given network. Each island is
identified with its port - its lowest vertex. The main problem are
the vertices at the same level - flat regions. The set of all maximal
vertex-islands determines a hierarchy.
For networks with weighted edges we can similarly define edge-islands.
The edge-islands algorithm is based on edge-cuts.
Both algorithms and some applications of islands in analysis of large
networks will be presented. We shall also describe several ways how
to determine values of vertices or weights of edges.
in a given network. Each island is
identified with its port - its lowest vertex. The main problem are
the vertices at the same level - flat regions. The set of all maximal
vertex-islands determines a hierarchy.
For networks with weighted edges we can similarly define edge-islands.
The edge-islands algorithm is based on edge-cuts.
Both algorithms and some applications of islands in analysis of large
networks will be presented. We shall also describe several ways how
to determine values of vertices or weights of edges.
François Bavaud, University of Lausanne,
``Generalized Factor Analysis for Contingency
Tables''
Abs:
Quotient dissimilarities constitute a broad aggregation-invariant
family; among them, 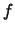 -dissimilarities
are Euclidean embeddable (cf. Bavaud, 2002). We present a non-linear
principal components analysis (NPA) applicable to
any quotient dissimilarity, based upon the spectral decomposition of
the central inertia. For -dissimilarities, the
same decomposition yields a non-linear correspondence analysis (NCA),
permitting us to modulate as finely as wished the
contributions of positive or negative deviations from independence.
The resulting coordinates exactly reproduce the original
dissimilarities between rows or between columns; however, Huygens's
weak principle is generally violated, as measured by
a quantity we call `eccentricity'.
-dissimilarities
are Euclidean embeddable (cf. Bavaud, 2002). We present a non-linear
principal components analysis (NPA) applicable to
any quotient dissimilarity, based upon the spectral decomposition of
the central inertia. For -dissimilarities, the
same decomposition yields a non-linear correspondence analysis (NCA),
permitting us to modulate as finely as wished the
contributions of positive or negative deviations from independence.
The resulting coordinates exactly reproduce the original
dissimilarities between rows or between columns; however, Huygens's
weak principle is generally violated, as measured by
a quantity we call `eccentricity'.
Mónica Bécue, Universitat Politècnica de Catalunya,
J. Pagès, Institut Nationales Supérieur, and
Campo-Elías
Pardo, Universidad Nacional de Colombia,
``Analysis of Cross-Language Open-Ended Questions Through
MFACT''
Abs:
International surveys lead to multilingual open-ended
responses. By grouping the answers for the same categories from
different countries, sets of comparable category-documents are
obtained. The methodology here presented, called multiple factor
analysis of contingency tables (MFACT), provides a representation of
all of the documents in a common reference space, on the one hand,
and of all of the words in a common reference space, on the other
hand; these both spaces are related by transition formulae. This
methodology allows a direct generalized canonical
analysis approach to analyzing multiple contingency tables as well as
for keeping correspondence analysis-like features. It works from the
raw data, without any previous translation. An example, extracted from
a large international survey in four countries, illustrates the
potential of this approach.
Halima Bensmail and Hamparsum Bozdogan, University of
Tennessee, ``Bayesian Unsupervised
Clustering for Mixed Data with Missing Observations''
Abs:
Here we try to develop and broaden the application areas of a new
statistical modeling technology which will cover a research study on
unsupervised classification with mixed data using multidimensional
scaling and Bayesian approach.
We attempt to make a bridge and apply Bayesian multidimensional
scaling for unsupervised clustering. This new methodology is
formulated in the multivariate non-Gaussian settings. We propose a new
way of clustering observations described by a mixed collection of
variables (nominal, ordinal and numerical). We, then use a
non-parametric clustering procedure based on optimally scaling the
large data and estimate the distribution of the object scores
obtained. We propose a multivariate kernel distribution as
non-parametric distribution for the
variables, this distribution is characterized by a variety of window
widths that controls the degree of smoothness of the estimate and a
variety of robust covariance matrices. This gives a variety of
flexible models to choose from. The prior choice here is challenging
especially when dealing with the window width distribution for that we
use some conjugate and Entropy based prior to overcome this
difficulties.
Another challenging part of cluster analysis is to propose a criteria
that help us choosing the number of clusters. We use here a Bayesian
information complexity ICOMP criterion (Bozdogan 1988) for choosing
the best window width, the right robust matrix and the optimal number
of clusters k.
Patrice Bertrand, GET-ENST Bretagne, and Ghazi Bel Mufti,
ESSEC, ``Loevinger's Measures of Rule Quantity for Assessing Cluster
Stability''
Abs:
We present a method for measuring clustering stability
under the removal of a few objects from a set of objects to be partitioned.
Measures of stability of an
individual cluster are defined as Loevinger's measures of rule quality.
The stability of an
individual cluster can be interpreted as a weighted mean of the
inherent stabilities in
the isolation and cohesion of the examined cluster respectively. The
design of the method enables
us to measure also the stability of a partition, that can be viewed as
a weighted mean of
the stability measures of all clusters in the partition.
As a consequence, an approach is derived for
determining the optimal number of clusters of
a partition.
Furthermore, using a Monte Carlo test, a probability significance is
computed in order to
assess how likely any stability measure is, under a null model
that specifies the absence of cluster stability.
In order to illustrate the potential of the method, we present
stability measures that
were obtained by using the batch K-Means algorithm on artificial
data sets and on Iris data.
Lynne Billard, University of Georgia, ``Symbolic Data Analysis:
An Overview of Principles and Some Descriptive Statistics''
Abs:
This paper looks at measures of dependence for
symbolic interval-valued data. A method is given to calculate
an empirical copula for a bivariate interval-valued variable. This copula
is then used to determine an empirical formula for calculating
Spearman's rho for such data. The methodology is illustrated
from a set of hematocrit-hemoglobin data and the results compared
with Pearson's product-moment correlation coefficient.
David Birnbaum, University of Pittsburgh, and David Dubin,
University of Illinois at Urbana-Champaign,
``Measuring Similarity in the Contents of Medieval Miscellany
Manuscripts''
Abs:
Edit distance for strings is measured in terms of the smallest
number of specific stepwise modifications (insertions,
deletions, transpositions, or replacements of characters) required to
make a transition from one state to another. We describe our
experiments with an analogous measure for larger units of analysis,
namely texts copied in medieval miscellany manuscripts. The goal of the
project is to describe the likely process employed by medieval scribes
in compiling these manuscripts, and the data consists of the
manuscripts' (virtual) tables of contents. The process of compiling a
miscellany manuscript is different from the process of copying prose
text, and one inserts, deletes, transposes, or replaces constituent
texts in a miscellany manuscript differently than one inserts, deletes,
transposes, or replaces words in continuous prose. We present an
algorithm for measuring similarity that is informed by those
differences, and hierarchical cluster analyses on the contents of
approximately one hundred manuscripts.
Hans-Hermann Bock, University of Aachen,
``Classification in the Life Span of Chikio Hayashi''
Abs: This talk reviews the origin and development of cluster analysis
and classfication theory during the life span of Chikio Hayashi, one
of the founders of the Japanese Classification Society (JCS) and of
the International Federation of Classification Societies (IFCS). It
presents a survey of important streams of research in the last 40
years, intermingled with personal reminiscences of Hayashi's activities.
Nicholas I. Bohnen, Marius Buliga, and Gregory M.
Constantine, University of Pittsburgh,
``Classifying the State of Parkinsonism by Using Electronic Force
Platform Measures of Balance''
Abs: Several measures of balance obtained from quiet stance
on an electronic force platform are described. These
measures were found to discriminate patients with
Parkinson's disease (PD) from normal control subjects.
First-degree relatives of patients with PD show greater
variability on these measures. A primary goal is to
develop sensitive measures that would be capable of
identifying impaired balance in early stages of
non-clinical PD. We developed a trinomial logistic model
that classifies a subject as either normal,
pre-parkinsonian, or parkinsonian taking as input the
measures developed from the platform data.
Kathy Bogie, Jiayang Sun, and Xiaofeng Wang,
Case Western University, ``Mining Huge-p-Small-n Data and
New Image Registration Procedures''
Abs:
This paper is concerned with developing effective procedures for
analyzing sequences of image data from neuromuscular electrical
stimulation (NMES) experiments. The data are large in its dimension
and small in its subject sample size. In addition, images taken at
different sessions from one subject may not align spatially; and
artifacts can arise from on-off moments if images are not aligned
temporally. We develop a spatial and a temporal registration schemes;
they are applicable to image data beyond the NMES experiments. We
study a statistical mapping method for analyzing large image data,
simultaneously; it leads to an efficient procedure for computing ``FDR
map'' to determine whether a change is clinically relevant or
spurious.
Stefan Born, Liebig University,
and Lars Schmidt-Thieme, University of Freiburg
``Optimal Discretization of Quantitative Attributes for Association
Rules''
Abs:
Association rules for objects with quantitative attributes
require the discretization of these attributes to limit the
size of the search space. As each such discretization might
collapse attribute levels that need to be distinguished for
finding association rules, optimal discretization strategies
are of interest. In 1996 Srikant and Agrawal formulated an
information loss measure called measure of partial completeness
and claimed that equidepth partitioning (i.e. discretization
based on base intervals of equal support) minimizes
this measure. We prove that in many cases equidepth
partitioning is not an optimal solution of the corresponding
optimization problem. In simple cases an exact solution can be calculated,
but in general optimization techniques have to be applied to
find good solutions.
Helena Brás Silva, Paula Brito, and Joaquim Costa,
University of Porto,
``Clustering and Validation Using Graph Theory: Application to Data
Sets with Numerical and Categorical Values''
Abs:
Applying graph theory to clustering, we propose a partitional
clustering method and a clustering tendency index, which may be
applied to data sets with numerical and categorical values. No initial
assumptions about the data set are requested by the method. The
partitional algorithm is based on graph colouring and uses an extended
greedy algorithm. The number of clusters and the partition that best
fits the data set are selected according to the optimal clustering
tendency index value. The key idea of this index is that there are k
well-separated and compact clusters, if a complete k-partite graph can
be defined in the data set, after clustering. The clustering tendency
index can also identify data sets with no clustering structure. We
propose a partition quality evaluation index and some evaluation
indexes of clusters' density and isolation, which select the best
partitions between the candidates resulting from the clustering
method. We have applied our methodology on simulated and real data
sets, so as to evaluate its reliability. This study has showed that
the method is efficient; in particular, for detecting non spherical
clusters and is robust as concerns outliers. Our methodology has been
compared with some classical clustering methods, namely k-means and
hierarchical, and using some validation indexes present in the
literature.
Matevz Bren, University of Maribor, and Vladimir Batagelj,
University of Ljubljana, ``Compositional Data Analysis with
R''
Abs:
R (at http://www.r-project.org/) is `GNU S'--a language and environment
for statistical computing and graphics. R is similar to the award-winning
S system, which was developed at Bell Laboratories by John Chambers et al.
It provides a wide variety of statistical and graphical techniques
(linear and nonlinear modelling, statistical tests, time series analysis,
classification, clustering, and others). Further extensions can be provided
as packages.
We started to develop the R package MixeR for the compositional data analysis
that provides support for:
- operations on compositions:
perturbation and power multiplication, subcomposition with or without
residuals, centering of the data, solving perurbation equations, computing
Aitchison's, Euclidean, Bhattacharyya distances, compositional
Kullback-Leibler divergence, and so forth
- graphical presentation of compositions in ternary diagrams and
tetrahedrons
with additional features: barycenter, geometric mean of the data set,
the percentiles lines, marking and coloring of subsets of the data set,
theirs geometric means, notation of individual data in the set, and
so forth.
We illustrate the use of MixeR with some real data.
François Brucker, GET-ENST Bretagne, ``Bijection Between
Dissimilarities and Binary Realizations''
Abs:
One of the aim of numerical taxonomy is to associate a preindexed
clustering system to a dissimilarity. Bertrand (2000) has shown that
if the clusters of a dissimilarity are exactly the maximal cliques
of its threshold graphs, there is a bijection between the set of all
dissimilarities and a class of preindexed clustering systems.
Since a graph can have an exponential number of maximal cliques,
finding all the clusters of a given dissimilarity is practically
impossible. Thus, classically, a given dissimilarity is approximated
by a dissimilarity of a given type whose clusters are easily
computable like ultrametrics, robinsonian dissimilarities or
quasi-ultrametrics.
The computability of those particular models comes from the fact that
their maximal cliques are generated by pairs of elements. We show
that this idea can be generalized to any dissimilarity by changing
the definition of a cluster. Defining a cluster by the intersection
of all the maximal cliques containing a pair of elements (called
binary realization), we show that there is a bijection between the set
of dissimilarities and a class of preindexed clustering
systems. Moreover the computation of all the binary realizations can be
performed in polynomial time for any dissimilarity.
Gilles Celeux, INRIA, ``Choosing a Model for Purposes of
Classification''
Abs:
We advocate the usefulness of taking into account the modeling purpose
when selecting a model. Two situations are considered to support
this idea: Choosing the number of components in a mixture model in
a cluster analysis perspective, and choosing a probabilistic model
in a supervised classification context. For this last situation we
propose a new criterion, the Bayesian Entropy Criterion, and
illustrate its behavior wtih numerical experiments. Those numerical
experiments show that this new criterion compares favorably with
the classical BIC criterion to choose a model minimizing the
prediction error rate.
Seong-San Chae, Daejeon University, Chansoo Kim, and William
D. Warde, Oklahoma State University, ``Cluster Analysis
Using Robust Estimators''
Abs:
Partitioning objects into closely related groups that have dierent
states allows to understand the underlying structure in the data set
treated. Several clustering algorithms with different kinds of
similarity measure are commonly used to find an optimal clustering or
close to original clustering. The retrieval ability of six chosen
clustering algorithms of using different correlation coeffcients is
evaluated using Rand's (1971) C values, presenting how
the resultant clustering is close to the original clustering. In the
procedure, the concept of informative variables is examined. The
retrieval ability is robust using the correlation coefficient with the
weighted likelihood estimators (WLE) in simulation study. Using the
data set from Spellman et al. (1998), the recovery levels of clusters
by the six clustering
algorithms with different correlation coe±cients, shrinkage-based
correlation(Cherepinsky
et al., 2003) and rank-based correlation (Bickel, 2003), are also
obtained and compared.
Anil Chaturvedi, Capital One Services, J. Douglas Carroll,
Rutgers University, and Vicki Caxsrtwright, Capital One Services, ``A
Three-Way, Three-Mode Hybrid Factor/Components Analysis Model''
Abs:
This paper presents an approach to enhancing the traditional
CANDECOMP/PARAFAC factor or components analysis model for three-way,
three-mode data. It enables the extraction of a combination of
continuous (a la the CANDECOMP/PARAFAC model of Carroll and Chang,
1970 and Harshman; see Harshman and Lundy, 1984) as well as discrete
factor scores and factor loadings for three-way, three-mode data, thus
enabling a richer exploration of the data at hand. It precludes the
assumption that there is only continuous structure in typical
three-way, three-mode data. Users can try to examine the true
structure present in the data - be it discrete or continuous. This
model is also a special case of a very general class of models and
methods called CANDCLUS presented by Carroll and Chaturvedi (1994). We
present various results from this three-way, three-mode
factor/components analysis model applied to data gathered from a
marketing research study.
Marie Chavent, University of Bordeaux,
``A Hausdorff Distance Between Hyper-Rectangles for
Clustering Interval Data''
Abs:
The Hausdorff distance between two sets is used in this paper to
compare hyper-rectangles. An explicit formula for the optimum class
prototype is found in the particular case of the Hausdorff distance
for the 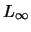 norm. When used for dynamical clustering of
interval data, this prototype will ensure that the clustering
criterion decreases at each iteration.
norm. When used for dynamical clustering of
interval data, this prototype will ensure that the clustering
criterion decreases at each iteration.
Chih-Chou Chiu, National Taipei University of Technology,
and Tian-Shyug Lee, Fu-Jen Catholic University, ``Integrating
Classification and Regression Trees with Multivariate Adaptive
Regression Splines in Mining Customer Credit Data''
Abs:
Credit scoring has become a very important task as the credit industry
has been experiencing tough competition during the past few years.
The artificial neural network is becoming a very popular alternative
in credit scoring models due to its associated memory characteristic
and generalization capability. However, the relative importance of
potential input variables and the long training process have often
long been criticized and hence limited its application in handling
credit scoring problems. The objective of the proposed study is to
explore the performance of credit scoring using two commonly discussed
data mining techniques-classification and regression tree (CART) and
multivariate adaptive regression splines (MARS). To demonstrate the
effectiveness of credit scoring using CART and MARS, credit scoring
tasks are performed on one bank credit card data set. As the results
reveal, CART and MARS outperform traditional discriminant analysis,
logistic regression, neural networks, and support vector machine (SVM)
approaches in terms of credit scoring accuracy and hence provide
efficient alternatives in implementing credit scoring tasks.
C. Cifaelli and L. Nieddu, University of Rome,
``An Iterative k-Means-Like Algorithm for
Statistical Face Recognition''
Abs:
A face recognition algorithm based on a iterated k-mean classifiation
technique (1) will be presented in this paper. The proposed algorithm,
when compared
with popular PCA algorithms for face recognition has an improved recognition
rate on various benchmark datasets (2). The algorithm considered in this
paper, unlike PCA, is not a dimensional reduction algorithm,
nonetheless it yields
barycentric-faces which can be used to determine different types of
face expressions,
light conditions and pose. The technique presented consists in
iteratively computing
centroyds faces until some conditions are met on the training set. The
accuracy PCA and k-mean methods have been evaluated under varying
expression, illumination and pose using standard face databases.
Gilles Clermont, Carson Chow, Greg Constantine, et al.,
University of Pittsburgh, ``Mathematical Modeling of Acute
Inflammation''
Abs:
A mathematical model involving a system of ordinary differential
equations has been developed with the goal of assisting the design
of therapies directed against the inflammatory consequences of
infection and trauma. Though the aim is to build a model of
greater complexity, which would eventually overcome some existing
limitations (such as a reduced subset of inflammatory
interactions, the use of mass action kinetics, and calibration to
circulating but not local levels of cytokines), the model can at
this time simulate certain disease scenarios qualitatively as well
as predicting the time course of cytokine levels in distinct
paradigms of inflammation in mice. A parameter search algorithm
is developed that aids in the identification of different regimes
of behaviour of the model and helps with its calibration to data.
Extending this mathematical model, with validation in humans, may
lead to the in silico development of novel therapeutic approaches
and real-time diagnostics.
Kevin Coakley, National Institute of Standards and Technology,
``A Classification Problem in Neutrino Physics''
Abs:
In CLEAN (Cryogenic Low Energy Astrophysics with Noble gases), a
proposed neutrino and dark matter detector, low energy neutrinos would
be detected based on scintillation light produced by neutrino-electron
and neutrino-nucleus
scattering in a spherical detection volume filled with liquid neon.
On average, the number of scintillation photons produced by a neutrino
event would be proportional to the energy deposited by the neutrino.
The scintillation photons Rayleigh scatter as they
propagate in the neon.
Thus, the scintillation photons do not travel in straight line
trajectories.
Further, each scintillation photon is
shifted to lower wavelength and diffusely re-emitted by
the detectors before ultimate detection.
Due to the radioactive decay of materials at the outer spherical wall of
the detection region, unwanted gamma rays are produced. As these gamma
rays propagate inward, they would be attenuated. However, due to energy
deposited by either Compton scattering or photoelectric absorption, gamma
rays would produce scintillation light. Since background events are
orders of magnitude more numerous than events of interest, statistical
methods for background discrimination are essential for enabling this
measurement system. We define an inner spherical fiducial volume that
occupies a fraction of the total spherical detection volume. By
design,
the probability that a background event occurs within the fiducial volume is
low.
In contrast, events of interest occur uniformly throughout the entire
detection volume. We assign events into one of two classes. The first
class consists of events which occur within the fiducial volume. The
second class consists of events which occur outside the fiducial volume.
The rate at which we assign background events to the first class is
the background rate. We develop classification
rules based on the estimated radial location of an event computed from the
spatial pattern of detected scintillation photons. One rule is based on
the approximate maximum likelihood estimate of event location. The other
is based on the centroid of the detected scintillation photons.
We calibrate the classification rules so that the probability of assigning
an event of interest to the first class is . We quantify the relative
performance of the two rules by estimating their associated background
rates.
(This talk is based on collaborative work with D. N. McKinsey of Yale
University.)
Brieuc Connan-Guez, INRIA-Rocquencourt, and Frabrice Rossi,
University of Paris IX-Dauphine, ``Phoneme Discrimination with
Functional Multi-Layer Perceptrons''
Abs:
In many situations, high dimensional data
can be considered as sampled functions. We recall in this paper how
to implement a Multi-Layer Perceptron (MLP) on such data by
approximating a theoretical MLP on functions thanks to basis
expansion. We illustrate the proposed method on a phoneme
discrimination problem.
Gregory Constantine, University of Pittsburgh,
``A Multidimensional Parameter Estimation Algorithm Based on
Optimal Linear Codes''
Abs:
Systems of Ordinary Differential Equations (ODE) yield
qualitatively different behaviour of the response
function as the input parameters change. In medical
applications, such as attempting to describe the reaction
of the immune system to accute illness, understanding
the different regimes of a response as a function of the
parameter space underlying the ODE system is of central
concern. An optimization search algorithm based on
optimal linear codes is developed to explore and partition
a multi-dimensional parameter space into classes that
yield essentially different regimes of the response
function. The algorithm searches disjoint regions of the
parameter space in accordance with the words of a code
and certain select cosets associated to these regions.
Depth searches are conducted in appropriately small
subregions near bifurcation points, by iteratively calling
the same algorithm within such subregions.
Raphaël Couturier, LIFC-IUT Belfort-Montbéliard,
Régis Gras, and F. Guillet, École Polytechnique de
l'Université de Nantes, ``Reducing
the Number of Variables Using Implicative Analysis''
Abs:
The interpretation of complex data with data mining
techniques is often a difficult
task. Nevertheless, this task may be simplified by reducing the
variables which
could be considered as equivalent. The aim of this paper is to
describe a new method for reducing the number of variables in a
large set of data.
Implicative analysis, which builds association rules with a measure
more powerful
than conditional probability, is used to detect quasi-equivalent
variables. This
technique has some advantages over traditional similarity analysis.
Di Cook, Iowa State University, ``Visualizing Class and
Cluster Structure beyond 3D''
Abs:
This talk will describe methods to look at cluster structure in
high-dimensional data relative to class labels. We will examine plots
of the data in relation to results from numerical classifiers such as
random forests, support vector machines and neural networks. The
reason to use graphics, in the spirit of exploratory data analysis,
seeks to develop a conceptual image and understanding of the process
generating our data. Much of the research being done on methods for
supervised classification dwells on predictive accuracy, which
although good and worthwhile is just a small part of a data
analysis. Ideally we come away from a data analysis with a story about
a real problem, and answers to pertinent questions, with a little more
understanding for our physical world. This is what this talk
addresses.
Marc Csernel, INRIA, Francisco de A. T. Carvalho,
Universidade Federal de Pernambuco,
and Yves Lechevallier, INRIA,
``Partitioning of Constrained Symbolic Data''
Abs:
Instead of containing a single value, each cell of a Symbolic table can contain
a set of values. Each row of this table contains a
symbolic description. Such a table can be constrained by domain knowledge,
expressed by rules, in a way similar to integrity constraints in a database.
We present a method to obtain a partition of the set of symbolic description
described in a table, into a fixed number of homogenous classes, on the bases
of a dissimilarity table. The partitioning algorithm minimizes a
criterion, which is based on the sum of dissimilarities between the description
belonging to the same cluster.
As comparison of couples of constrained symbolic descriptions
induces usually an exponential growing of computation times, a
pre-processing step, where symbolic descriptions are put on the
Normal Symbolic Form, is necessary in order to keep computation
time polynomial. The Normal Symbolic Form (NSF) is
a decomposition of symbolic description in such a way that only coherent
descriptions (i.e., which do not contradict the rules) are represented.
An example derived from biology is presented.
Guy Cucumel, Université du Québec à
Montréal,
``Average Consensus and  -consensus:
Comparison of Two Consensus Methods for Ultrametric Trees''
Abs:
Consensus methods are widely used to combine hierarchies defined on a
common set of n objects (Leclerc, 1998). Given a profile P = (T1, ,
Ti, , Tk) of k ultrametric trees, the average consensus (Lapointe and
Cucumel, 1997) allows to obtain a consensus solution that is
representative of the entire profile P by minimizing the sum of
squared distances between the initial profile and the consensus
(L2-consensus). As this problem is NP-complete, when the data set is
large, one has to use heuristics to resolve it. As a result, the
uniqueness and optimality of the solution is not certain. Moreover,
the convergence toward a solution is sometimes difficult. Chepoi and
Fichet (2000) have developed an algorithm that yields to a universal
L8-consensus in a maximum of n2 steps. The two methods will be
presented and compared on some numerical examples.
-consensus:
Comparison of Two Consensus Methods for Ultrametric Trees''
Abs:
Consensus methods are widely used to combine hierarchies defined on a
common set of n objects (Leclerc, 1998). Given a profile P = (T1, ,
Ti, , Tk) of k ultrametric trees, the average consensus (Lapointe and
Cucumel, 1997) allows to obtain a consensus solution that is
representative of the entire profile P by minimizing the sum of
squared distances between the initial profile and the consensus
(L2-consensus). As this problem is NP-complete, when the data set is
large, one has to use heuristics to resolve it. As a result, the
uniqueness and optimality of the solution is not certain. Moreover,
the convergence toward a solution is sometimes difficult. Chepoi and
Fichet (2000) have developed an algorithm that yields to a universal
L8-consensus in a maximum of n2 steps. The two methods will be
presented and compared on some numerical examples.
Ana Lorga da Silva, Universidade Lusofona de Humanidades e
Tecnologias, G. Saporta, CNAM, and H.
Bacelar-Nicolau, University of Lisbon,
``Missing Data and Imputation Methods in Partition of Variables''
Abs:
We deal with the effect of missing data under
a ``Missing at Random Model'' on classification of variables with
non-hierarchical methods. The partitions are compared by the Rand
index.
Francisco de A. T. Carvalho, Universidade Federal de Pernambuco,
Yves Lechevallier, INRIA-Rocquencourt, Renata M. C. R.
de Souza, Cidade Universitaria-Brazil, ``A Dynamic Clustering
Algorithm Based on 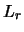 -Distances for Quantitative Data''
Abs:
Dynamic clustering methods aim to obtain both a single
partition of the input data
into a fixed number of clusters and the identification of a suitable
representation of each cluster simultaneously. In its adaptive version, at each
iteration of these algorithms there is a different distance for the comparison
of each cluster with its representation. In this paper, we present a dynamic
cluster method based on distances for quantitative data.
-Distances for Quantitative Data''
Abs:
Dynamic clustering methods aim to obtain both a single
partition of the input data
into a fixed number of clusters and the identification of a suitable
representation of each cluster simultaneously. In its adaptive version, at each
iteration of these algorithms there is a different distance for the comparison
of each cluster with its representation. In this paper, we present a dynamic
cluster method based on distances for quantitative data.
Stefano De Cantis and Antonino Oliveri, University of
Palermo, ``An Overview of
Collapsibility''
Abs: Collapsing over variables is a necessary procedure in much
empirical research. Consequences are yet not always properly
evaluated. In this paper, different definitions of collapsibility
(simple, strict, strong, etc.) and corresponding necessary and
sufficient conditions are reviewed and evaluated. We point
out the relevance and limitations of the main contributions within
a unifying interpretative framework. We deem such work to be useful
since the debate on the topic has often developed in terms that are
neither focused nor clear.
Sérgio R. de M. Queiroz and Francisco A. T. de
Carvalho, Universidade Federal de Pernambuco, ``A
Symbolic Model-Based Approach for Making Collaborative Group
Recommendations''
Abs:
In recent years, recommender systems have achieved great
success. Popular sites
give thousands of recommendations every day. However, despite the fact
that many activities are carried out in groups, like going to the
theater with friends, these systems are focused on recommending items
for sole users. This brings out the need for systems capable of
performing recommendations for groups of people, a domain that has
received little attention in the literature. In this article we
introduce a novel method of making collaborative recommendations for
groups, based on models built using techniques from symbolic data
analysis. Finally, we empirically evaluate the proposed method to see
its behaviour for groups of different sizes and degrees of
homogeneity, and compare the achieved results with a baseline
methodology.
Mark de Rooij, Leiden University, ``Scaling the Odds''
Abs:
The odds ratio is the main measure of association for contingency
tables. In the present paper a scaling of a basic set of odds
ratios is proposed through the singular value decomposition.
Properties valid for the relation between a basic set of odds
ratios and all odds ratios translate nicely into properties of the
singular vectors. Some simple structures are discussed that might
be used for diagnostic plotting. Estimates for the standard errors
and the bias are obtained using a jackknife procedure.
Key words: (log) odds ratio; inner product; singular value
decomposition.
Renata M. C. R. de Souza, Cidade Universitaria-Brazil,
Francisco A. T. de Carvalho, Universidade Federal de Pernambuco,
Camilo P.
Tenório, and Yves Lechevallier, INRIA-Rocquencourt, ``Dynamic
Clustering Methods for
Interval Data Based on Mahalanobis Distances''
Abs:
Dynamic cluster methods for interval data are presented. Two methods are
considered: the first method furnishes a partition of the input data and a
corresponding prototype (a vector of intervals) for each class by optimizing an
adequacy criterion which is based on Mahalanobis distances between vectors of
intervals. The second is an adaptive version of the first method. Experimental
results with artificial interval-valued data sets show the usefulness of these
methods. In general, the adaptive method outperforms the non-adaptive one
in terms of the quality of the clusters which are produced by the
algorithms.
Reinhold Decker, University of Bielefeld
``Self-Controlled Growing Neural Networks and Their Application to Pattern
Representation in Data Analysis''
Abs:
This presentation introduces a new growing neural network
approach for data analysis. The algorithm is similar to the one
suggested by Marsland et al. (2002) and Decker, Monien (2003)
concerning its structural design and it bears certain analogies
with the growing neural gas network introduced by Fritzke
(1995). However, the algorithm on hand is more parsimonious
regarding the number of parameters to be specified a priori,
which increases its autonomy with respect to the insertion of
new units or rather weight vectors during the adaptation
process.
To demonstrate its performance and flexibility the new algorithm
will be applied to synthetical 2D data with a distinct
heterogeneity with regard to the arrangement of the individual
data points as well as to real point of sale scanner data
provided by a German supermarket chain.
Markus Demleitner, University of Heidelberg,
Michael Kurtz, Harvard University, et al., ``Automated Resolution of Noisy
Bibliographic References''
Abs:
We describe a system used by the NASA Astrophysics Data System to
identify bibliographic references obtained from scanned article pages by
OCR methods with records in a bibliographic database. We analyze the
process generating the noisy references and conclude that the three-step
procedure of correcting the OCR results, parsing the corrected string
and matching it against the database provides unsatisfactory results.
Instead, we propose a method that allows a controlled merging of
correction, parsing and matching, inspired by dependency grammars. We
also report on the effectiveness of various heuristics that we have
employed to improve recall.
José G. Dias, Instituto Superior de Ciências do Trabalho
e da Empresa, ``Controlling the Level of Separation of Components
in Monte Carlo Studies of Latent Class Models''
Abs:
The paper proposes a new method to control the level of separation of
components using a single parameter. An illustration for the latent class
model (mixture of conditionally independent multinomial distributions) is
provided. Further extensions to other finite mixture models are discussed.
Edwin Diday, University of
Paris IX-Dauphine, ``Introduction to Spatial Classification''
Abs:
Indexed hierarchies and indexed clustering
pyramids are based on an underlying order for which each cluster
is connected. In this paper our aim is to extend standard pyramids
and their underlying one-to-one correspondence with Robinsonian
dissimilarities to spatial pyramids where each cluster is
``compatible'' with a spatial network given by a kind of
tessellation called ``m/k-network''. We focus on convex spatial
pyramids and we show that they are in one-to-one correspondence
with a new kind of dissimilarities. We give a building algorithm
for convex spatial pyramids illustrated by an example. We show
that spatial pyramids can converge towards geometrical pyramids.
We indicate finally that spatial pyramids can give better results
than Kohonen mappings and can produce a geometrical representation
of conceptual lattices.
Arta Doci and Peter Bryant, University of Colorado at Denver,
``An MDL Criterion for k-Means Clustering''
Abs:
In this presentation, we examine the use of a criterion based on the
Minimum Description Length (MDL) Principle to evaluate the results of
a k-means clustering procedure, in particular to select the
appropriate number of clusters. We present the criterion and give
results from the analysis of a number of data sets, and suggest some
possible further avenues for future development.
Pedro Domingos, University of Washington, ``A General
Framework for Mining Massive Data Streams''
Abs:
In many domains, data now arrives faster than we are able to mine it.
To avoid wasting this data, we must switch from the traditional
"one-shot" data mining approach to systems that are able to mine
continuous, high-volume, open-ended data streams as they arrive.
In this talk I will identify some desiderata for such systems,
and outline our framework for realizing them. A key property of our
approach is that it minimizes the time required to build a model on a
stream, while guaranteeing (as long as the data is i.i.d.) that the
model learned is effectively indistinguishable from the one that would
be obtained using infinite data. Using this framework, we have
successfully adapted several learning algorithms to massive data
streams, including decision tree induction, Bayesian network learning,
k-means clustering, and the EM algorithm for mixtures of Gaussians.
These algorithms are able to process on the order of billions of
examples per day using off-the-shelf hardware. Building on this, we
are currently developing software primitives for scaling arbitrary
learning algorithms to massive data streams with minimal effort.
Next: Abstracts E-N
Up: abstracts
Previous: abstracts